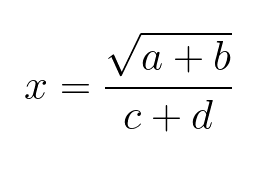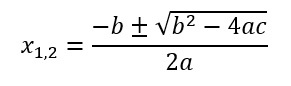Created by Jindřich Zdráhal
Každý algoritmus musí skončit v konečném počtu kroků.
Úloha, kterou potřebujeme vyřešit.
Každý krok algoritmu musí být jednoznačně a přesně definován. V každé situaci musí být jasné, který krok následuje.
Pro stejné vstupy by program měl mít stejný výstup.
Použité zdroje:
Algoritmus by měl řešit problémy obecně a ne konkrétně.
Tzn., nepotřebuji kalkulačku, která umí jen sčítat 2+3, ale kalkulačku, která umí sčítat čísla.
Algoritmus je přesný návod či postup, kterým lze vyřešit daný typ úlohy.
Toto a vlastnosti algoritmu převzato z Wikipedie pod licencí CC BY-SA 3.0
Algoritmus je přesný návod k řešení konkrétního problému.
Algoritmus má alespoň jeden výstup.
Algoritmus se skládá z jednoduchých (elementárních) kroků.
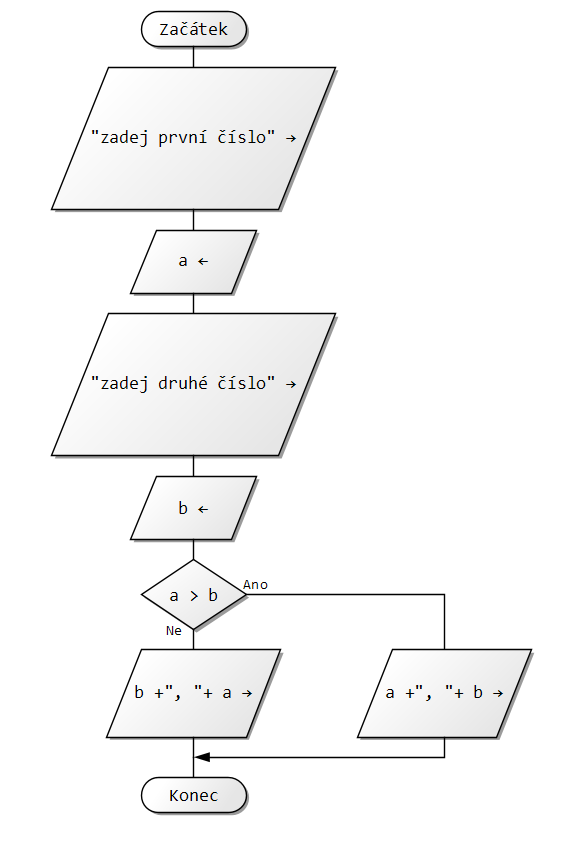
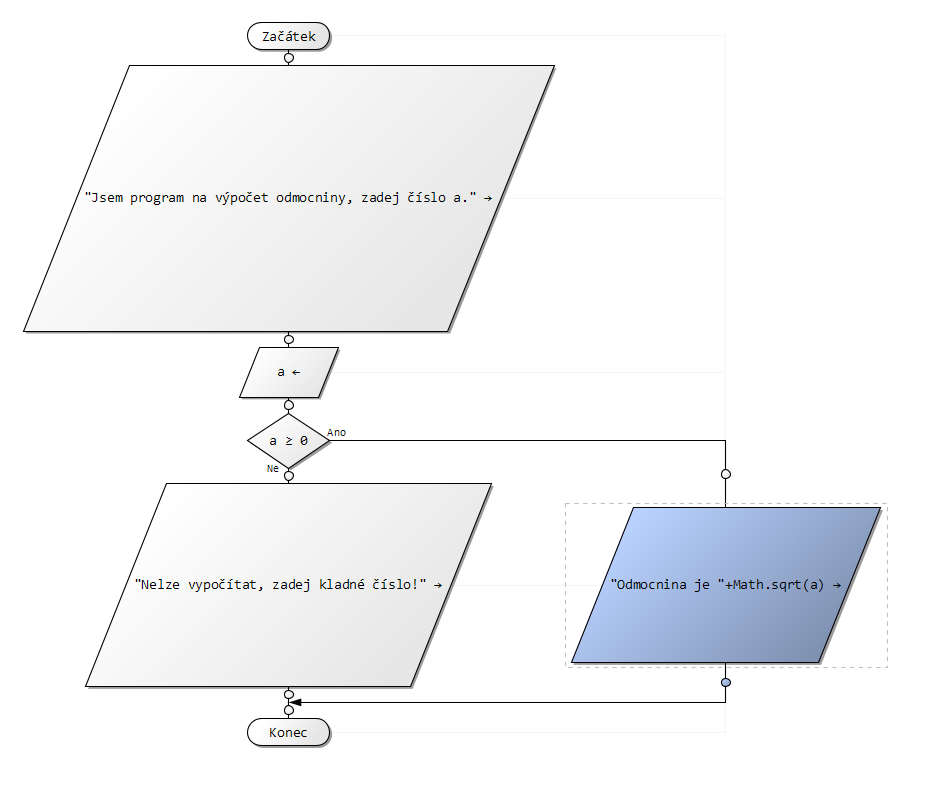
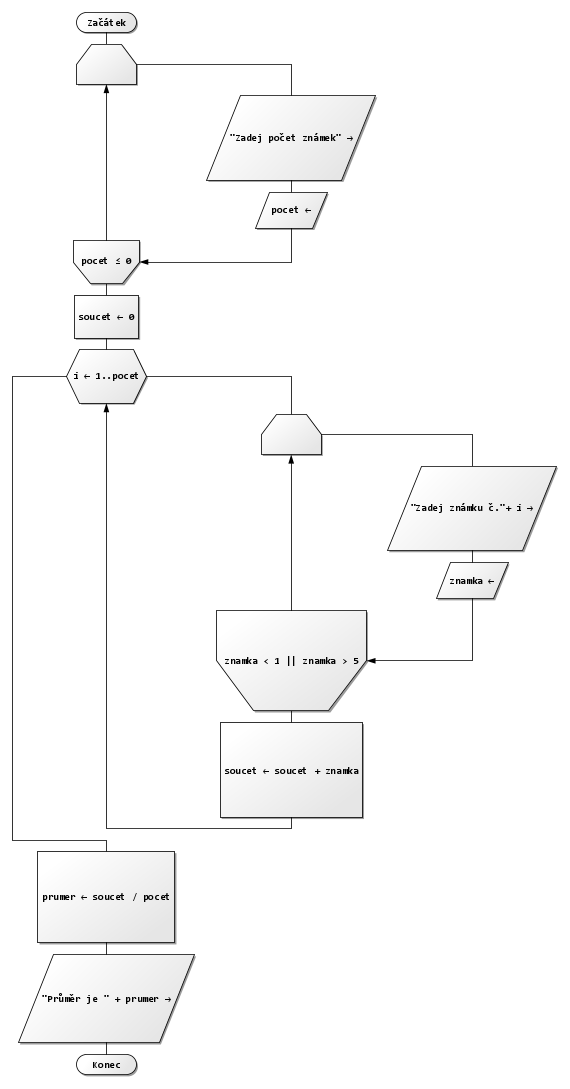
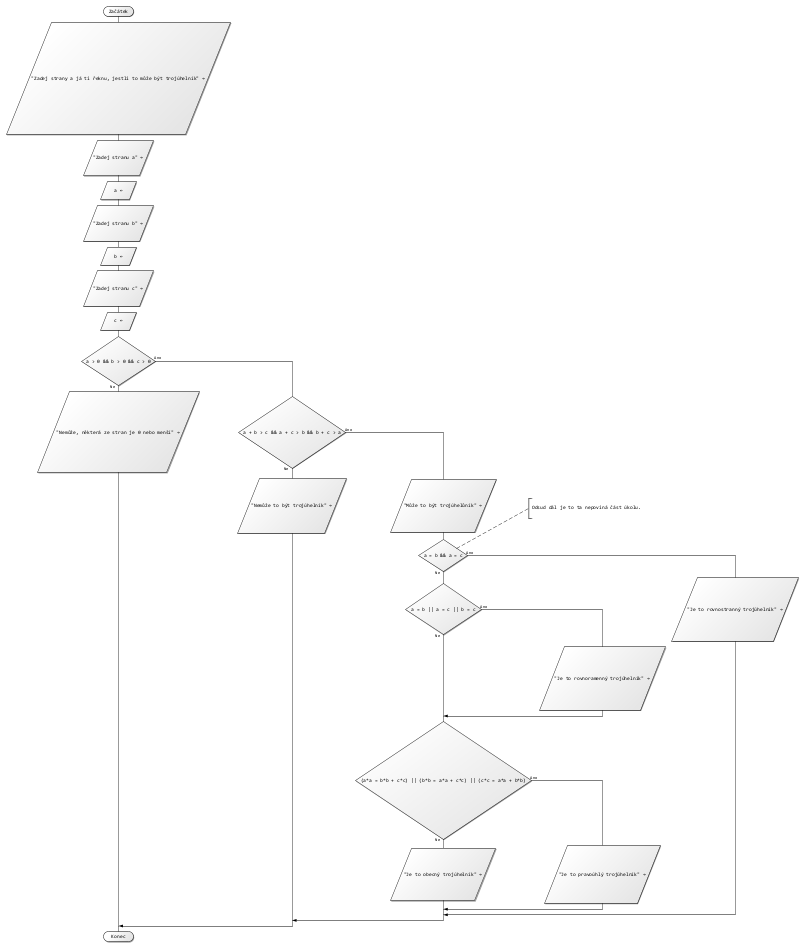
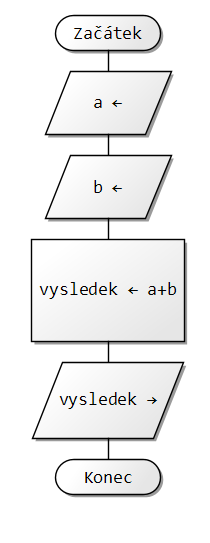
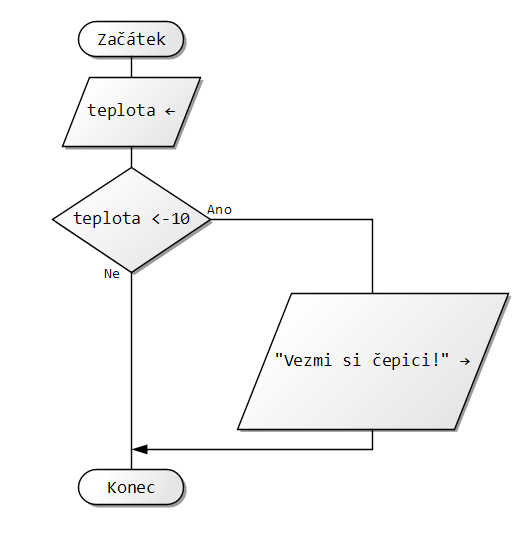
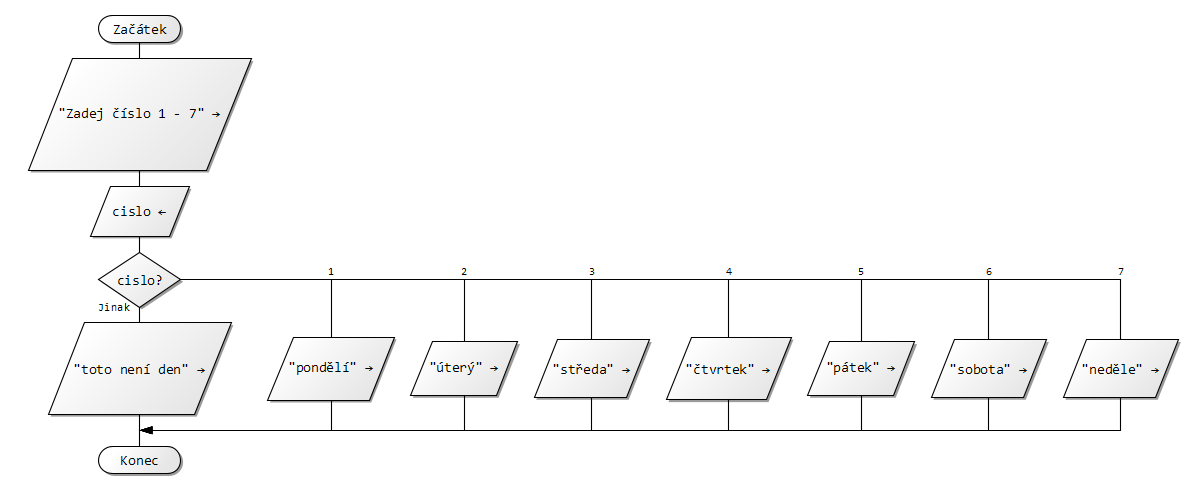
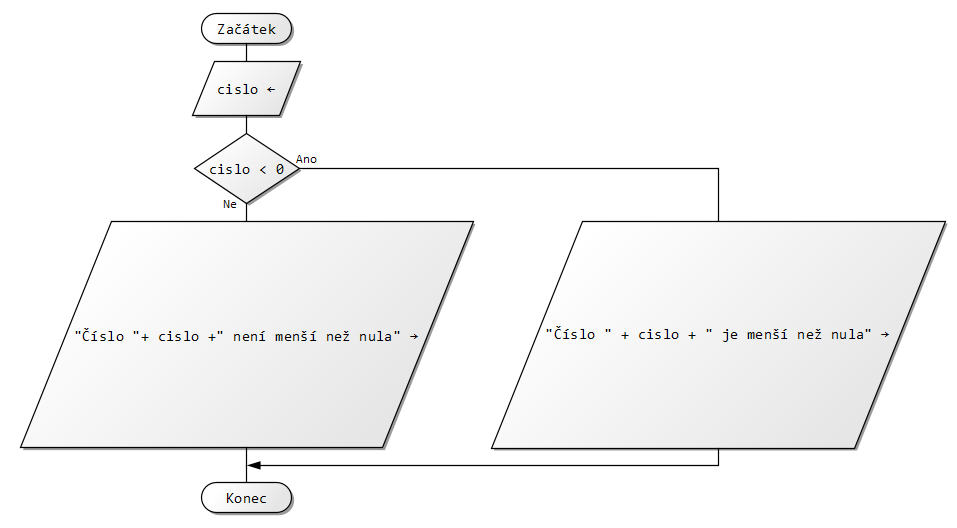
Vytvoř vývojový diagram algoritmu, kterému zadáš 2 čísla a on ti vypíše, které je větší a které je měnší.
Informace jsou data prezentovaná v takovém kontextu, který dává smysl a význam.
Informace tedy slouží ke zpracování, skladování nebo přenášení dat.
Například číslo 120/80 patří mezi data, pokud jej ale ozřejmíme jako dnešní ranní krevní tlak pacienta v milimetrech rtuťového sloupce, již je z něj užiteč ná informace.
![]() 01 - Software - data, informace.docx
01 - Software - data, informace.docx
Známé i z běžného života. Například návody, postupy, kuchařské recepty.
Výhody
Nevýhody
Zkuste se podívat na prezentaci paní Mgr. Pavlíny Mihačové, kde to hezky vysvětluje: ZPŮSOBY ZÁPISU ALGORITMŮ
Texty převzaty (a někde i pozměněny) z textu od pana učitele Vojáčka Algoritmizace
Algoritmus zapsaný v jazyce, kterému rozumí i počítač.
Výhody
Nevýhody
Programovací jazyk je prostředek pro zápis algoritmů, jež mohou být provedeny na počítači. Zápis algoritmu ve zvoleném programovacím jazyce se nazývá program.
Programovací jazyk je komunikačním nástrojem mezi programátorem a počítačem. Programovací jazyk je vlastně soubor pravidel pro zápis algoritmu, odborně řečeno se jedná o formální jazyk.
Převzato z Wikipedie pod licencí CC BY-SA 3.0
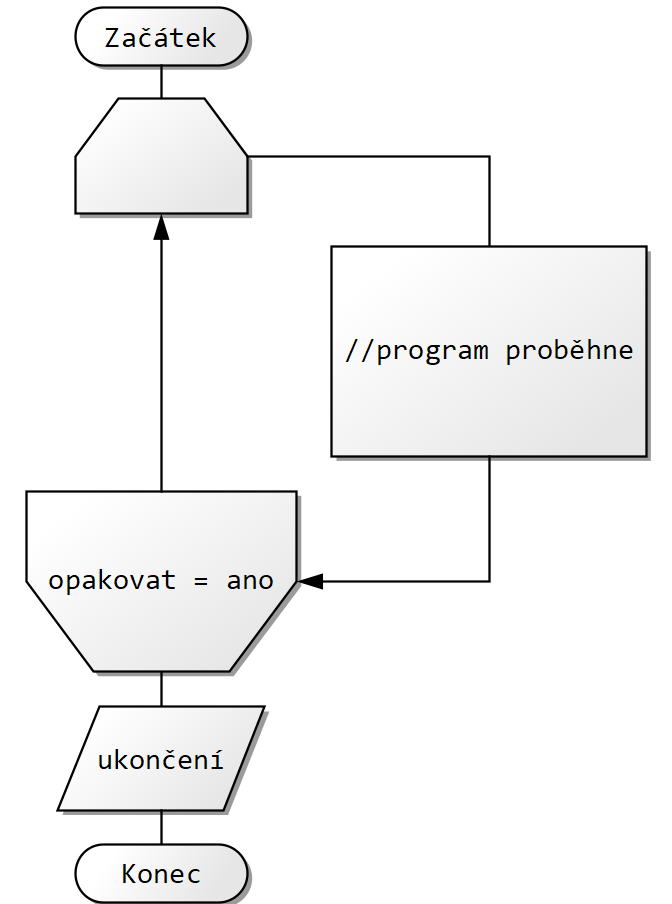
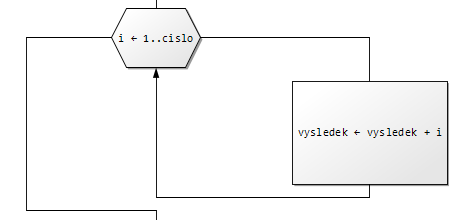
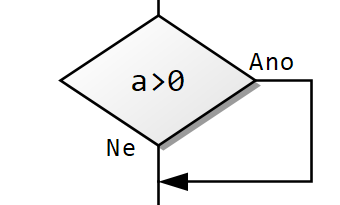
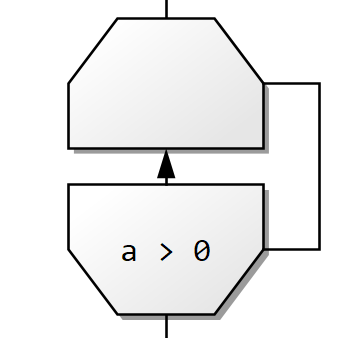
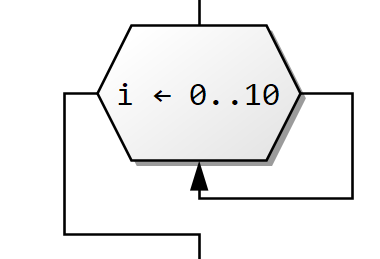
Na začátku cyklu se vyhodnotí podmínka a pokud platí, tak se cyklus provede. Vrátí se na začátek a pokud podmínka stále platí, tak se cyklus opakuje.
Z tohoto webu si můžete zdarma stáhnout program na tvorbu vývojových diagramů od Miroslava Bartyzala , který budeme používat. Jestli budete chtít, tak je tam k němu i uživatelská příručka, ale ten program je tak jednoduchý, že to za to nestojí 😉
Všechny obrázky vztažené k vývojovým diagramům jsem dělal v tomto programu.
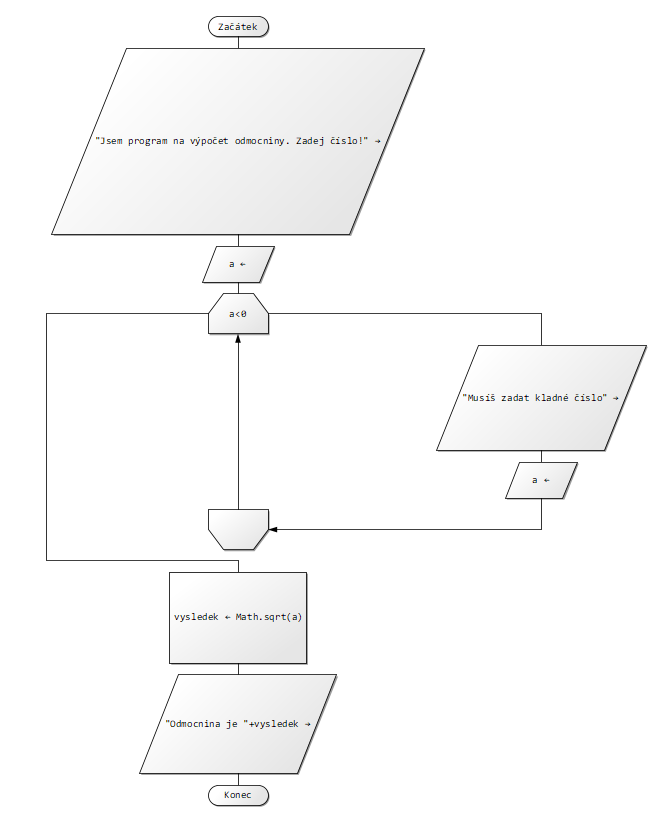
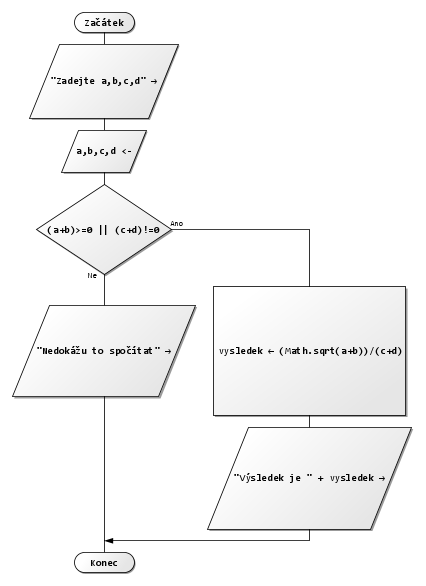
1. Vytvořte algoritmus (zapiš vývojovým diagramem) pro výpočet výrazu:
Pamatujte:
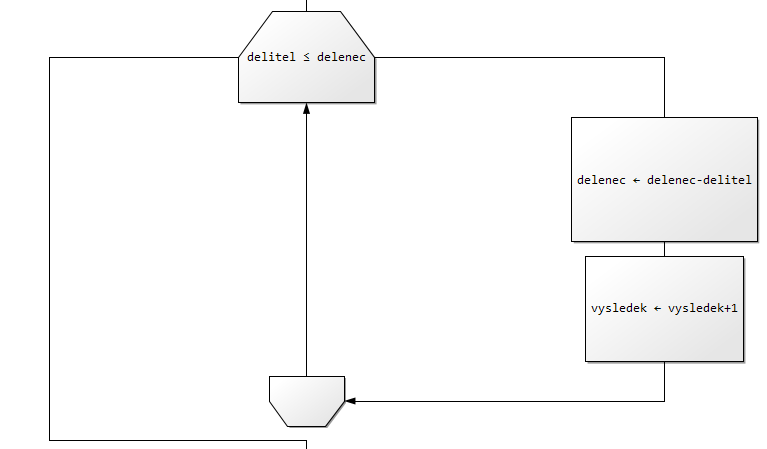
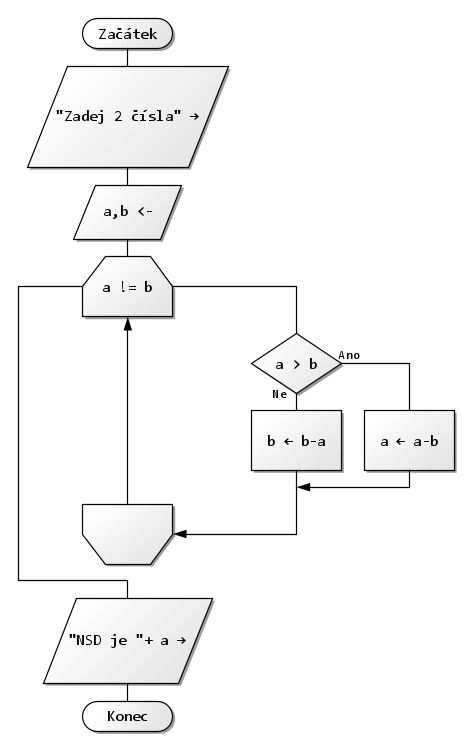
2. Vyatvořte algoritmus (zapište vývojovým diagramem) pro výpočet Největšího společného dělitele (NSD)
Princip řešení:
Např.:
NSD čísel a = 27 a b = 12 je 3
Postup:
Data jsou informace, které jsou zaznamenány a uchovány ve formě digitálního záznamu.
Data mohou být různého druhu, jako například čísla, texty, obrázky nebo zvuky.
Vhodné tam, kde se problém dá zapsat jako matematický problém (rovnice).
Výhody
Nevýhody
Jedno opakování cyklu se jmenuje jedna iterace.
Vhodné tam, kde je jenom několik možností. Např.: rozvrh hodin, výrokové tabulky, přehledy a podobně
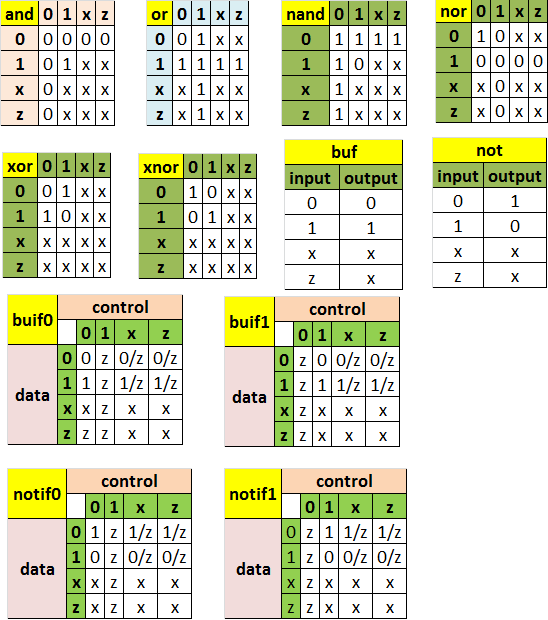
Obrázek je převzatý z ASIC-System on Chip-VLSI Design pod licencí CC BY-SA 2.5
Výhody
Nevýhody
V podstatě se jedná o slovní zápis s grafickým naznačením struktury.
Výhody
Nevýhody
Grafické symboly s textem.
Výhody
Nevýhody
Datová struktura je konkrétní způsob organizace dat v paměti počítače, který zajišťuje, aby mohla data být používána efektivně.
Datová struktura umožňuje uchovávat a zpracovávat množinu dat stejného typu nebo různorodých, ale logicky souvisejících dat.
![]() 01 - Software - data, informace.docx
01 - Software - data, informace.docx
Najděte si, co znamenají a naučte se je.
![]() 13 - Pole, seznam, zásobník, fronta, strom.pdf
13 - Pole, seznam, zásobník, fronta, strom.pdf
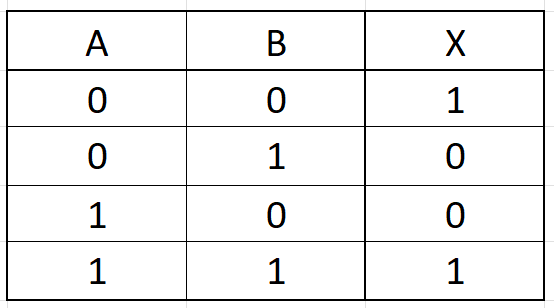
Výrok je každé sdělení (gramaticky vyjádřené oznamovací větou), o němž má smysl tvrdit, že je pravdivé (platí, 1), nebo nepravdivé (neplatí, 0).
Jednoduché (atomické nebo elementární) výroky jsou výroky, které neobsahují logické spojky. (např. „Jmenuji se Jan.“, „Včera pršelo.“, „79 je prvočíslo“). Jsou z logického hlediska dále nedělitelné a jsou prezentovány výrokovými proměnnými (nebo také výrokovými symboly).
Složené výroky jsou výroky, které vznikly z jednoduchých výroků použitím logických spojek.
Převzato z Wikipedie pod licencí CC BY-SA 3.0
Platí tehdy, pokud se vstupy rovnají
Datové struktury můžeme dělit podle různých kritérií.
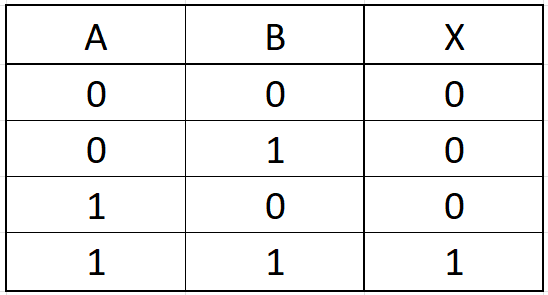
Platí jen tehdy, pokud platí obě podmínky
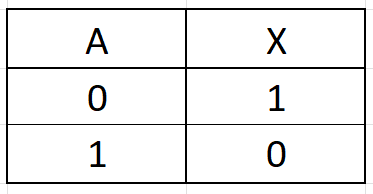
Otáčí hodnotu vstupu
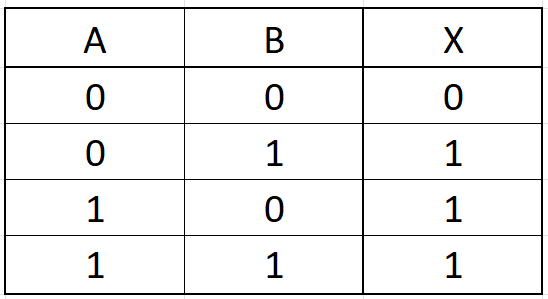
Platí tehdy, pokud platí alespoň jedna z podmínek
Do základních datových struktur patří proměnná, pole, záznam a objekt. S těmito datovými strukturami se nejčastěji setkáváme u většiny programovacích jazyků.
Do odvozených datových struktur patří seznam, zásobník, fronta a strom.
![]() 13 - Pole, seznam, zásobník, fronta, strom.pdf
13 - Pole, seznam, zásobník, fronta, strom.pdf
Samostatné hodnoty jsou jednotlivé hodnoty, které nejsou spojeny s žádnými jinými hodnotami, zatímco strukturovaná data jsou data, která jsou uspořádána určitým způsobem.
Strukturovaná data jsou obvykle uspořádána do tabulek, záznamů nebo jiných datových struktur, které umožňují snadné vyhledávání a manipulaci.
Samostatné hodnoty se obvykle používají pro jednoduché výpočty nebo porovnávání, zatímco strukturovaná data se používají pro složitější úlohy, jako je analýza dat a vytváření zpráv.
-32 768 -- + 32 767
2 byte
- 2 147 483 648 -- + 2 147 483 647
4 byte
základní celočíselný datový typ
Proměnné si můžeme představit jako šuplíčky se jmény (abychom je mohli pohodlně volat), které uchovávají určitá data(čísla, znaky, texty,...).
Proměnná je místo v paměti, kde se uchovávají hodnoty. Hodnotu můžeme uložit a později ji zase načíst zpět.
Proměnné jsou jen dočasné - při ukončení programu se vymažou.
Pro pojmenování proměnných používáme camel case.
-128 -- +127
1 byte
- 9 223 372 036 854 775 808 -- +9 223 372 036 854 775 807
8 byte
S těmito se setkáme u většiny programovacích jazyků. Jsou jednodušší.
int a = 30; // normálně v desítkové
int b = 030 //když to začíná 0 tak v osmičkové
int c = 0x30 //0x začíná číslo v šestnáctkové
Tyto struktury jsou složitější.
4 byte
bez desetinné čárky
s desetinnou čárkou
Lineární datová struktura.
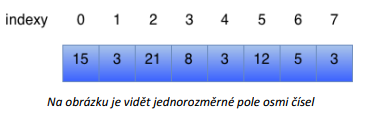
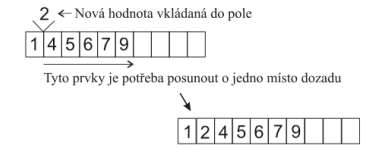
Obsahuje posloupnost proměnných stejného datového typu uložených v řadě za sebou a je chápáno jako jeden celek.
Vytváří se deklarací, kde určíme:
V paměti počítače je adresována pouze první položka pole, zbytek je adresován za pomoci indexů. Indexy začínají (většinou) NULOU.
Musíme hlídat, abychom se nepokoušeli dostat na prvek s indexem, který už (ještě) nemáme.
Výhoda: vyskytuje se v téměř všech programovacích jazycích, je jednoduché na používání
Nevýhoda: umožňuje ukládat jenom data jednoho datového typu. V JAVĚ je statické (nejde jednoduše zvětšit jeho velikost), blbě se vhládá doprostřed a odebírá z prostředku.
Tyto datové struktury budeme probírat až při programování. Takže tady jsme si je uvedli jenom, že existují.
Lineární dynamická datová struktura.
Lineární = data jsou ukládána za sebou.
Dynamická = je to budováno postupně, tzn. na začátku nevíme jak bude seznam velký.
V paměti je seznam adresován svým prvním prvkem. Každý prvek obsahuje adresu následujícího prvku = ukazatel.
Výhody: snadno vkládám nebo odebírám hodnoty odkudkoliv.
Nevýhody: pomalejší přístup k jednotlivým hodnotám (musím jít na začátek a pak tam "doskákat"). Pokud potřebuji předcházející hodnotu, tak musím znovu od začátku.
 | |
| Fronta | |
| V programování je fronta abstraktní, dynamický datový typ, typu FIFO | |
|
8 byte
základní reálný datový typ
Datové typy dělíme v JAVĚ na dvě velké skupiny:
Teorie nám říká, že v základních datových typech jsou přímo hodnoty, které jsme tam zadali.
V referenčních je jenom odkaz (reference) na místo v paměti, kde je skutečná hodnota.
Datový typ určuje, jaká data mohou být v proměnné uložena a co se s nimi dá provádět. Datový typ je určený:
Programovací jazyky mají některé datové typy předdefinované. Z nich pak můžeme tvořit další datové typy.
znak
2 byte
zapisuje se mezi jednoduché uvozovky např.:
char c = 'x';
Zajímavost - můžeme ho zapsat jako:
pouze dvě hodnoty:
Datový typ se proměnné přiřazuje při její deklaraci. Díky tomu jsou tyto typy známé hned při překladu zdrojového kódu a díky tomu může odhalit některé typy chyb. Také je to vhodnější pro optimalizaci.
Na druhou stranu nemůžeme do této proměnné ukládat data jiného datového typu.
Toto je třeba programovací jazyk JAVA
Hodnoty proměnných a jejich datové typy vznikají až za běhu programu. Proto nemohou být kontrolovány při kompilaci, ale až za běhu. Na druhou stranu můžeme do proměnné postupně ukládat data různého datového typu.
To je dobré pro flexibilitu programování a hloupé pro optimalizaci.
Proto jsou jazyky s dynamickým typováním jsou obecně pomalejší.
Pokaždé, když chci použít nějakou proměnnou, tak ji musím deklarovat a případně i inicializovat.
Deklarace je v podstatě to, že řeknu programu, že budu mít proměnnou jménem xy a bude určitého typu. Takže si vlastně jenom vytvořím šuplík do kterého budu ukládat data. K tomuto šuplíku mám jeho jméno a typ dat, která do něj budu dávat. Dělá se to tak, že napíšu typ proměnné a její jméno.
Např.: chci používat proměnnou pocet a chci aby to bylo celé číslo.
int pocet;
Tím mám tu proměnnou, ale nemá žádnou hodnotu. Takže když ji budu nějakým způsobem používat (třeba k ní něco přičítat pocet++ tak to nebude fungovat).
První přiřazení hodnoty do proměnné se nazývá inicializace.
pocet = 100;
Pokud už na začátku vím, jako hodnotu tam budu chtít, tak to můžu spojit do jednoho kroku:
int pocet = 100;