Created by Honza Šuráň
 priznaku muze stacit
priznaku muze stacit  trenovacich bodu pro natrenovani
trenovacich bodu pro natrenovani bud neni linearni, nebo je vysoce numericky nestabilni, a inverze se pocita blbe
bud neni linearni, nebo je vysoce numericky nestabilni, a inverze se pocita blbe
priznaku  , hodnoty priznaku
, hodnoty priznaku 

 jsou nezname koeficienty
jsou nezname koeficienty je hodnota nahodnych vlivu
je hodnota nahodnych vlivu

 se nazyva intercept a odpovida ocekavane vychozi hodnote
se nazyva intercept a odpovida ocekavane vychozi hodnote  pri nulovych priznacich, napr. v pripade ceny bytu to je cena za zprostredkovani nabidky
pri nulovych priznacich, napr. v pripade ceny bytu to je cena za zprostredkovani nabidkymejme  , oznacme
, oznacme

pak muzeme zkracene psat

 ziskany metodou nejmensich ctvercu je za predpokladu
ziskany metodou nejmensich ctvercu je za predpokladu  nestranny, tj.
nestranny, tj. 
![\begin{align}
\text{E} \mathbf{Y} = \text{E}\left(\mathbf{X} \mathbf{w} + \mathbf{\epsilon} \right) &= \mathbf{X} \mathbf{w} + \text{E} \mathbf{\epsilon} = \mathbf{X} \mathbf{w} \\[7pt]
\text{E} \hat{\mathbf{w}}_{OLS}
&= \text{E}\left(\mathbf{X}^T X \right)^{-1} \mathbf{X}^T \mathbf{Y} \\
&= \left(\mathbf{X}^T\mathbf{X}\right)^{-1} \mathbf{X}^T \text{E } \mathbf{Y} \\
&= \left(\mathbf{X}^T \mathbf{X}\right)^{-1} \mathbf{X}^T\mathbf{X}\mathbf{w} \\
&= \mathbf{w}
\end{align}](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjM1LjY4OGV4IiBoZWlnaHQ9IjE5LjUwOWV4IiBzdHlsZT0idmVydGljYWwtYWxpZ246IC05LjE3MWV4OyIgdmlld0JveD0iMCAtNDQ1MS4xIDE1MzY1LjYgODM5OS44IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1TVElYV0VCTUFJTi00NSIgZD0iTTU5NyAxNjlsLTQ2IC0xNjloLTUzOXYxOWM3NyA1IDg3IDE4IDg3IDk1djQzNmMwIDc0IC0xMiA4OSAtODcgOTN2MTloNTMwbDQgLTE0M2gtMjVjLTE1IDkwIC0zOCAxMDUgLTE1NCAxMDVoLTEzMWMtMjggMCAtMzUgLTQgLTM1IC0zNnYtMjIwaDE1MWM4NiAwIDEwMSAxNyAxMTMgOTZoMjN2LTIzNGgtMjNjLTEyIDg0IC0yNyA5NyAtMTEzIDk3aC0xNTF2LTI0M2MwIC00MiAyNyAtNDcgMTAxIC00N2gzNmMxNDMgMCAxODYgMjYgMjMxIDEzMiBoMjhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLVNUSVhXRUJOT1JNQUxCLTFENDE4IiBkPSJNNjk5IDY3NnYtMjVjLTM0IC01IC01NCAtMTYgLTY4IC0zOWwtMTkxIC0zMTF2LTE3OGMwIC03OCAxMyAtOTEgOTIgLTk4di0yNWgtMzQ3djI1YzgzIDcgOTMgMjggOTMgMTAzdjEzNmwtMTgwIDMyOGMtMTkgMzQgLTQ5IDU3IC04MyA1OXYyNWgzMzV2LTI1bC0yNyAtMmMtNDAgLTMgLTU0IC02IC01NCAtMjljMCAtOSAxMiAtMzYgMjQgLTU5bDEyMCAtMjMybDEwOSAxNzhjMjYgNDMgNDEgODIgNDEgMTAyYzAgMjkgLTE2IDM3IC04NCA0MnYyNSBoMjIwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1TVElYV0VCTUFJTi0zRCIgZD0iTTYzNyAzMjBoLTU4OXY2Nmg1ODl2LTY2ek02MzcgMTIwaC01ODl2NjZoNTg5di02NloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtU1RJWFdFQk1BSU4tMjgiIGQ9Ik0zMDQgLTE2MWwtMTIgLTE2Yy0xNTggOTAgLTI0NCAyNTkgLTI0NCA0MjljMCAxODUgODcgMzI5IDI0NyA0MjRsOSAtMTZjLTEzOSAtMTE5IC0xNzAgLTIxMiAtMTcwIC00MDVjMCAtMTg2IDMwIC0yOTkgMTcwIC00MTZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLVNUSVhXRUJOT1JNQUxCLTFENDE3IiBkPSJNNjk5IDBoLTM0MHYyNWwyOCAyYzM1IDIgNTIgMTEgNTIgMjhjMCAxMiAtOSAzNSAtMjEgNTRsLTEwMSAxNjJsLTM4IC01MWMtNzUgLTEwMSAtOTQgLTEzMiAtOTQgLTE1M2MwIC0yNiAyMCAtMzYgODEgLTQydi0yNWgtMjUwdjI1YzUwIDYgNzQgMTkgMTA0IDU2bDE3NSAyMjFsLTE5OCAyOTFjLTMxIDQ1IC00NCA1NSAtODAgNTh2MjVoMzQ2di0yNWwtMzEgLTJjLTM2IC0yIC00OCAtMTAgLTQ4IC0zMWMwIC0xMiAyIC0xNyAxNSAtMzcgbDk3IC0xNTBsNTYgNzdjNDcgNjUgNTggODQgNTggMTA2YzAgMjQgLTEzIDMxIC01MSAzNWwtMjEgMnYyNWgyNTB2LTI1Yy03NSAtNyAtMTAxIC0yNSAtMTg4IC0xNDZsLTgwIC0xMTFsMTgyIC0yODNjNDcgLTczIDYzIC04NSA5NyAtODZ2LTI1WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1TVElYV0VCTk9STUFMQi0xRDQzMCIgZD0iTTcwNyA0NjF2LTI0Yy0yNiAtNSAtMzcgLTE2IC01MCAtNTBsLTE1NSAtNDAxaC0yM2wtMTAyIDMxMGwtMTI1IC0zMTBoLTI0bC0xNDggMzc0Yy0yNSA2MiAtMzEgNzIgLTU3IDc3djI0aDIyMnYtMjRjLTI4IC00IC0zOCAtMTEgLTM4IC0yOGMwIC0xMyAxMiAtNDQgMzkgLTExNWw0NSAtMTE4bDY4IDE3MWMtMiA2IC00IDEyIC02IDE5Yy0xOSA2NiAtMjAgNjcgLTU5IDcxdjI0aDIzNHYtMjRjLTM4IC0zIC00OCAtOCAtNDggLTI0IGMwIC0xMCA3IC0zOCAyNyAtMTA2YzIwIC03MCAyNCAtODUgMzQgLTEyN2wzNSA5NGMyOSA3OCA0NCAxMTUgNDQgMTI4YzAgMjMgLTExIDMxIC00OCAzNXYyNGgxMzVaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLVNUSVhXRUJNQUlOLTJCIiBkPSJNNjM2IDIyMGgtMjYxdi0yNjFoLTY2djI2MWgtMjYxdjY2aDI2MXYyNjFoNjZ2LTI2MWgyNjF2LTY2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1TVElYV0VCTk9STUFMSS0xRDcxNiIgZD0iTTQzMCA0NDFsLTE5IC0xMzJoLTE1Yy03IDQ2IC0yNCAxMDUgLTkzIDEwNWMtODIgMCAtMTM5IC05NyAtMTYxIC0xNjdoMTgxbC01IC0zNmgtMTg1Yy03IC0yMCAtNyAtNDEgLTcgLTY2YzAgLTY0IDM3IC0xMDEgOTIgLTEwMWM1OCAwIDEwOSAzNCAxNDQgNjhsMTIgLTE0Yy01MyAtNjAgLTExMSAtMTA5IC0xOTQgLTEwOWMtOTQgMCAtMTQwIDY5IC0xNDAgMTUyYzAgMTQyIDExNCAzMDAgMjY5IDMwMGM0OSAwIDU1IC0yMCA4MyAtMjAgYzEyIDAgMTkgMTEgMjMgMjBoMTVaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLVNUSVhXRUJNQUlOLTI5IiBkPSJNMjkgNjYwbDEyIDE2YzE1MyAtOTIgMjQ0IC0yNTkgMjQ0IC00MjljMCAtMTg1IC04OCAtMzI3IC0yNDcgLTQyNGwtOSAxNmMxNDIgMTE3IDE3MCAyMTEgMTcwIDQwNWMwIDE4NyAtMjUgMzAyIC0xNzAgNDE2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1TVElYV0VCTUFJTi0zMDIiIGQ9Ik0tNzUgNTA3aC0zNGwtMTIyIDEwM2wtMTIxIC0xMDNoLTM0bDEyNCAxNjdoNjJaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLVNUSVhXRUJOT1JNQUxJLTFENDQyIiBkPSJNNzEyIDQyMGMwIC0xOTggLTE1NiAtNDMxIC00MDkgLTQzMWMtMTQ5IDAgLTI1MyA5NiAtMjUzIDIzM2MwIDIwMyAxNTggNDQ3IDQxMyA0NDdjMTY3IDAgMjQ5IC0xMjMgMjQ5IC0yNDl6TTU5NiA0NDNjMCAxMDcgLTQwIDE4OSAtMTQxIDE4OWMtMjMyIDAgLTI4NCAtMzEzIC0yODQgLTQ1NWMwIC05NyA2MiAtMTUwIDE0MCAtMTUwYzIxMiAwIDI4NSAyNzUgMjg1IDQxNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtU1RJWFdFQk5PUk1BTEktMUQ0M0YiIGQ9Ik02NjggMTkwbC02MSAtMTkwaC01NjlsNCAxNmgxN2M3NSAwIDk5IDI4IDEwNyA2MmwxMTggNDc3YzQgMTYgNyAzNiA3IDQ1YzAgMTkgLTE0IDM3IC03NiAzN2gtMThsNCAxNmgzMjdsLTQgLTE2aC0xOGMtNzUgMCAtOTYgLTI2IC0xMDUgLTYzbC0xMjIgLTQ4MWMtNCAtMTUgLTUgLTI5IC01IC0zMWMwIC0yMiAyOCAtMjQgNDAgLTI0aDEyMmMxMDIgMCAxNTMgMjIgMTk5IDExNWM3IDExIDEyIDIzIDE3IDM3aDE2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1TVElYV0VCTk9STUFMSS0xRDQ0NiIgZD0iTTY4MCA2NjhsLTUzIC0yMjFoLTE2YzEgOCAxIDE2IDEgMjRjMCA4NCAtNDggMTYwIC0xNjAgMTYwYy00MyAwIC0xMjEgLTI2IC0xMjEgLTk3YzAgLTY5IDYxIC0xMTEgMTE3IC0xNTljNTkgLTQ5IDExOCAtMTA3IDExOCAtMTk0YzAgLTk5IC04NyAtMTkxIC0yNDQgLTE5MWMtOTQgMCAtMTI1IDM4IC0yMDEgMzhjLTI1IDAgLTM5IC0xMSAtNTUgLTM4aC0xNmw2MCAyMzZoMTZjMCAtMTAgMSAtMjEgMSAtMzEgYzMgLTc5IDQwIC0xNjcgMTcxIC0xNjdjMTI3IDAgMTU2IDcxIDE1NiAxMzZjMCAzNSAtMTggNjggLTQ2IDk2Yy0zMCAzMSAtNzggNjcgLTExNCAxMDJjLTI4IDI4IC03MyA4MiAtNzMgMTMxYzAgODEgNjUgMTc1IDIyMyAxNzVjODMgMCAxNDAgLTM3IDE4MyAtMzdjMjAgMCAzNCAyMiAzNyAzN2gxNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtU1RJWFdFQk5PUk1BTEktMUQ0NDciIGQ9Ik02NzAgNjUzbC00NiAtMTc5aC0xNmMyIDE3IDUgNDQgNSA3MWMwIDY2IC01OCA3MSAtOTkgNzFoLTk4bC0xMzMgLTUzOGMtMiAtOSAtNSAtMTYgLTUgLTI1YzAgLTIxIDE2IC0zNyA3NiAtMzdoMjFsLTQgLTE2aC0zMjlsNCAxNmgxOGM3OCAwIDk4IDI4IDEwNiA2MmwxMzMgNTM4aC05MWMtODMgMCAtMTUzIC02MSAtMTcxIC0xNDJoLTE2bDQ2IDE3OWg1OTlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLVNUSVhXRUJOT1JNQUxJLTFENDRCIiBkPSJNODEwIDY1M2wtNCAtMTZoLTRjLTY5IDAgLTk4IC0zMiAtMTM1IC03NGwtMTg3IC0yMTNsOTYgLTI2NmMxMiAtMzQgMjkgLTY4IDc5IC02OGgxNGwtNCAtMTZoLTI4MWw0IDE2aDExYzM4IDAgNjcgNCA2NyA0MWMwIDggLTEgMTYgLTQgMjZsLTY5IDE5NGwtMTgxIC0yMDFjLTkgLTEwIC0xMiAtMTkgLTEyIC0yOGMwIC0xOSAxOCAtMzIgNTYgLTMyaDIybC00IC0xNmgtMjQ5bDQgMTZjNTQgNyAxMDMgMzcgMTQwIDc3bDIwOCAyMzBsLTg1IDIzMSBjLTExIDMxIC0yOCA4MyAtMTAyIDgzaC05bDQgMTZoMjgzbC00IC0xNmgtMTljLTMwIDAgLTUyIC00IC01MiAtMzVjMCAtOCAyIC0xNyA2IC0yOGw2MCAtMTc5bDE2NCAxODRjOSAxMSAxNSAyMyAxNSAzNGMtMSAxNiAtMTMgMjQgLTQ1IDI0aC05bDQgMTZoMjIyWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1TVElYV0VCU0laRTEtMjgiIGQ9Ik0zODIgLTEzNHYtMzBjLTE0MiAxMzQgLTI0MyAzNDMgLTI0MyA2MTVjMCAyNjcgMTAxIDQ4MSAyNDMgNjE1di0zMGMtOTAgLTExMCAtMTYyIC0yODIgLTE2MiAtNTg1YzAgLTMwNiA3MiAtNDc1IDE2MiAtNTg1WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1TVElYV0VCU0laRTEtMjkiIGQ9Ik04NiAxMDM2djMwYzE0MiAtMTM0IDI0MyAtMzQzIDI0MyAtNjE1YzAgLTI2NyAtMTAxIC00ODEgLTI0MyAtNjE1djMwYzkwIDExMCAxNjIgMjgyIDE2MiA1ODVjMCAzMDYgLTcyIDQ3NSAtMTYyIDU4NVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtU1RJWFdFQk1BSU4tMjIxMiIgZD0iTTYyMSAyMjBoLTU1N3Y2Nmg1NTd2LTY2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1TVElYV0VCTUFJTi0zMSIgZD0iTTM5NCAwaC0yNzZ2MTVjNzQgNCA5NSAyNSA5NSA4MHY0NDljMCAzNCAtOSA0OSAtMzAgNDljLTEwIDAgLTI3IC01IC00NSAtMTJsLTI3IC0xMHYxNGwxNzkgOTFsOSAtM3YtNTk3YzAgLTQzIDIwIC02MSA5NSAtNjF2LTE1WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2NywwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKC0xMSwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsMzU3MCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQk1BSU4tNDUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQk5PUk1BTEItMUQ0MTgiIHg9IjYxMSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTUFJTi0zRCIgeD0iMTYxMSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTUFJTi00NSIgeD0iMjU3NSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDMzNTMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQk5PUk1BTEItMUQ0MTciIHg9IjMzMyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTk9STUFMQi0xRDQzMCIgeD0iMTA1NiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTUFJTi0yQiIgeD0iMjAwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTk9STUFMSS0xRDcxNiIgeD0iMjkwOCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTUFJTi0yOSIgeD0iMzMzOCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0MDkxLDEyODkpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJNQUlOLTQ1IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjExLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJOT1JNQUxCLTFENDMwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJNQUlOLTMwMiIgeD0iNTUzIiB5PSI2MyI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDcyMiwtMTUwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtU1RJWFdFQk5PUk1BTEktMUQ0NDIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJOT1JNQUxJLTFENDNGIiB4PSI3MzIiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJOT1JNQUxJLTFENDQ2IiB4PSIxNDQxIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MDE1LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwzNTcwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTUFJTi0zRCIgeD0iMjc3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJOT1JNQUxCLTFENDE3IiB4PSIxMjQxIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJOT1JNQUxCLTFENDMwIiB4PSIxOTYzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJNQUlOLTJCIiB4PSIyOTA4IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJNQUlOLTQ1IiB4PSIzODE2IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJOT1JNQUxJLTFENzE2IiB4PSI0NDI3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJNQUlOLTNEIiB4PSI1MTM1IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJOT1JNQUxCLTFENDE3IiB4PSI2MDk5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJOT1JNQUxCLTFENDMwIiB4PSI2ODIxIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDEyODkpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJNQUlOLTNEIiB4PSIyNzciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQk1BSU4tNDUiIHg9IjEyNDEiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxODUyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJTSVpFMS0yOCIgeD0iMCIgeT0iLTIwMSI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ2OCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTk9STUFMQi0xRDQxNyIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtU1RJWFdFQk5PUk1BTEktMUQ0NDciIHg9IjEwMjEiIHk9IjU4MyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJOT1JNQUxJLTFENDRCIiB4PSIxNzY1IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJTSVpFMS0yOSIgeD0iMjU3NSIgeT0iLTIwMSI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDMwNDQsNjAyKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtU1RJWFdFQk1BSU4tMjIxMiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtU1RJWFdFQk1BSU4tMzEiIHg9IjY4NSIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1ODM1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJOT1JNQUxCLTFENDE3IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTk9STUFMSS0xRDQ0NyIgeD0iMTAyMSIgeT0iNTgzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQk5PUk1BTEItMUQ0MTgiIHg9IjcxMzEiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTQ1OCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQk1BSU4tM0QiIHg9IjI3NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyNDEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQlNJWkUxLTI4IiB4PSIwIiB5PSItMjAxIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDY4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJOT1JNQUxCLTFENDE3IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTk9STUFMSS0xRDQ0NyIgeD0iMTAyMSIgeT0iNTgzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQk5PUk1BTEItMUQ0MTciIHg9IjE3NjUiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQlNJWkUxLTI5IiB4PSIyNDg3IiB5PSItMjAxIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjk1Niw2MDIpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTUFJTi0yMjEyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTUFJTi0zMSIgeD0iNjg1IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUxMzUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQk5PUk1BTEItMUQ0MTciIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJOT1JNQUxJLTFENDQ3IiB4PSIxMDIxIiB5PSI1ODMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTUFJTi00NSIgeD0iNjQzMiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTk9STUFMQi0xRDQxOCIgeD0iNzI5MyIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwtMjIwNSkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQk1BSU4tM0QiIHg9IjI3NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyNDEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQlNJWkUxLTI4IiB4PSIwIiB5PSItMjAxIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDY4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJOT1JNQUxCLTFENDE3IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTk9STUFMSS0xRDQ0NyIgeD0iMTAyMSIgeT0iNTgzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQk5PUk1BTEItMUQ0MTciIHg9IjE3NjUiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQlNJWkUxLTI5IiB4PSIyNDg3IiB5PSItMjAxIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjk1Niw2MDIpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTUFJTi0yMjEyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTUFJTi0zMSIgeD0iNjg1IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUxMzUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQk5PUk1BTEItMUQ0MTciIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJOT1JNQUxJLTFENDQ3IiB4PSIxMDIxIiB5PSI1ODMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTk9STUFMQi0xRDQxNyIgeD0iNjQzMiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTk9STUFMQi0xRDQzMCIgeD0iNzE1NCIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwtMzY3MSkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQk1BSU4tM0QiIHg9IjI3NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTk9STUFMQi0xRDQzMCIgeD0iMTI0MSIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9zdmc+)


 nul a jednicek (ci vice hodnot)
nul a jednicek (ci vice hodnot) pomery poctu
pomery poctu  vuci celkovemu mnozstvi,
vuci celkovemu mnozstvi,  , napr.
, napr. 
 by mela byt nezaporna
by mela byt nezaporna

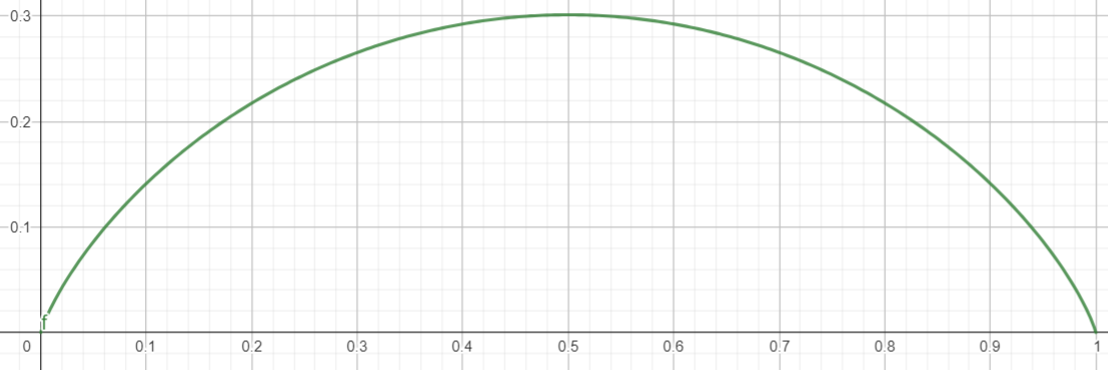
![[0,\frac{1}{2}]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjUuMzM5ZXgiIGhlaWdodD0iMy41MDlleCIgc3R5bGU9InZlcnRpY2FsLWFsaWduOiAtMS4xNzFleDsiIHZpZXdCb3g9IjAgLTEwMDYuNiAyMjk4LjYgMTUxMC45IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1TVElYV0VCTUFJTi01QiIgZD0iTTI5OSAtMTU2aC0yMTF2ODE4aDIxMXYtMjVoLTgzYy0zNCAwIC01MiAtMTIgLTUyIC00OHYtNjY2YzAgLTQwIDE5IC01NCA1MiAtNTRoODN2LTI1WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1TVElYV0VCTUFJTi0zMCIgZD0iTTQ3NiAzMzBjMCAtMTcyIC02MyAtMzQ0IC0yMjYgLTM0NGMtMTcxIDAgLTIyNiAxODYgLTIyNiAzNTBjMCAxNzcgNjkgMzQwIDIzMCAzNDBjMTMxIDAgMjIyIC0xNDEgMjIyIC0zNDZ6TTM4MCAzMjVjMCAyMDggLTQ0IDMyNSAtMTMyIDMyNWMtODMgMCAtMTI4IC0xMTggLTEyOCAtMzIxczQ0IC0zMTcgMTMwIC0zMTdjODUgMCAxMzAgMTE1IDEzMCAzMTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLVNUSVhXRUJNQUlOLTJDIiBkPSJNODMgLTE0MWwtMTAgMTljNTUgMzcgODMgNzQgODMgMTA3YzAgNyAtNiAxMyAtMTQgMTNzLTE4IC00IC0yOSAtNGMtMzcgMCAtNTggMTcgLTU4IDUxczI0IDU3IDYwIDU3YzQ1IDAgODAgLTM1IDgwIC04N2MwIC02MCAtNDMgLTEyMyAtMTEyIC0xNTZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLVNUSVhXRUJNQUlOLTMxIiBkPSJNMzk0IDBoLTI3NnYxNWM3NCA0IDk1IDI1IDk1IDgwdjQ0OWMwIDM0IC05IDQ5IC0zMCA0OWMtMTAgMCAtMjcgLTUgLTQ1IC0xMmwtMjcgLTEwdjE0bDE3OSA5MWw5IC0zdi01OTdjMCAtNDMgMjAgLTYxIDk1IC02MXYtMTVaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLVNUSVhXRUJNQUlOLTMyIiBkPSJNNDc0IDEzN2wtNTQgLTEzN2gtMzkxdjEybDE3OCAxODljOTQgOTkgMTMwIDE3NSAxMzAgMjYwYzAgOTEgLTU0IDE0MSAtMTM5IDE0MWMtNzIgMCAtMTA3IC0zMiAtMTQ3IC0xMzBsLTIxIDVjMjEgMTE3IDg1IDE5OSAyMDggMTk5YzExMyAwIDE4NSAtNzcgMTg1IC0xNzZjMCAtNzkgLTM5IC0xNTQgLTEyOCAtMjQ4bC0xNjUgLTE3NmgyMzRjNDIgMCA2MyAxMSA5NiA2N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtU1RJWFdFQk1BSU4tNUQiIGQ9Ik0yNDUgLTE1NmgtMjExdjI1aDg4YzM1IDAgNDcgMTUgNDcgNDZ2NjY4YzAgMzUgLTEzIDU0IC01MSA1NGgtODR2MjVoMjExdi04MThaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJNQUlOLTVCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJNQUlOLTMwIiB4PSIzMzMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQk1BSU4tMkMiIHg9IjgzNCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwODQsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyODYsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI0NzMiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0PgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJNQUlOLTMxIiB4PSI4NCIgeT0iNjI5Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTUFJTi0zMiIgeD0iODQiIHk9Ii01OTkiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJNQUlOLTVEIiB4PSIxOTY1IiB5PSIwIj48L3VzZT4KPC9nPgo8L3N2Zz4=) , klesajici na
, klesajici na ![[\frac{1}{2}, 1]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjUuMzM5ZXgiIGhlaWdodD0iMy41MDlleCIgc3R5bGU9InZlcnRpY2FsLWFsaWduOiAtMS4xNzFleDsiIHZpZXdCb3g9IjAgLTEwMDYuNiAyMjk4LjYgMTUxMC45IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1TVElYV0VCTUFJTi01QiIgZD0iTTI5OSAtMTU2aC0yMTF2ODE4aDIxMXYtMjVoLTgzYy0zNCAwIC01MiAtMTIgLTUyIC00OHYtNjY2YzAgLTQwIDE5IC01NCA1MiAtNTRoODN2LTI1WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1TVElYV0VCTUFJTi0zMSIgZD0iTTM5NCAwaC0yNzZ2MTVjNzQgNCA5NSAyNSA5NSA4MHY0NDljMCAzNCAtOSA0OSAtMzAgNDljLTEwIDAgLTI3IC01IC00NSAtMTJsLTI3IC0xMHYxNGwxNzkgOTFsOSAtM3YtNTk3YzAgLTQzIDIwIC02MSA5NSAtNjF2LTE1WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1TVElYV0VCTUFJTi0zMiIgZD0iTTQ3NCAxMzdsLTU0IC0xMzdoLTM5MXYxMmwxNzggMTg5Yzk0IDk5IDEzMCAxNzUgMTMwIDI2MGMwIDkxIC01NCAxNDEgLTEzOSAxNDFjLTcyIDAgLTEwNyAtMzIgLTE0NyAtMTMwbC0yMSA1YzIxIDExNyA4NSAxOTkgMjA4IDE5OWMxMTMgMCAxODUgLTc3IDE4NSAtMTc2YzAgLTc5IC0zOSAtMTU0IC0xMjggLTI0OGwtMTY1IC0xNzZoMjM0YzQyIDAgNjMgMTEgOTYgNjdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLVNUSVhXRUJNQUlOLTJDIiBkPSJNODMgLTE0MWwtMTAgMTljNTUgMzcgODMgNzQgODMgMTA3YzAgNyAtNiAxMyAtMTQgMTNzLTE4IC00IC0yOSAtNGMtMzcgMCAtNTggMTcgLTU4IDUxczI0IDU3IDYwIDU3YzQ1IDAgODAgLTM1IDgwIC04N2MwIC02MCAtNDMgLTEyMyAtMTEyIC0xNTZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLVNUSVhXRUJNQUlOLTVEIiBkPSJNMjQ1IC0xNTZoLTIxMXYyNWg4OGMzNSAwIDQ3IDE1IDQ3IDQ2djY2OGMwIDM1IC0xMyA1NCAtNTEgNTRoLTg0djI1aDIxMXYtODE4WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTUFJTi01QiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDMzMywwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjQ3MyIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtU1RJWFdFQk1BSU4tMzEiIHg9Ijg0IiB5PSI2MjkiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJNQUlOLTMyIiB4PSI4NCIgeT0iLTU5OSI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQk1BSU4tMkMiIHg9IjEwNDciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQk1BSU4tMzEiIHg9IjE0NjQiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQk1BSU4tNUQiIHg9IjE5NjUiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==)

pro vice hodnot:

podle priznaku  , ktery deli na
, ktery deli na  s prislusnymi pomery velikosti z puvodni mnoziny
s prislusnymi pomery velikosti z puvodni mnoziny  :
:

 odhad vektoru koeficientu
odhad vektoru koeficientu  v konkretnim bode
v konkretnim bode  vztahem
vztahem


za predopkladu plati

 je tedy bodovym odhadem stredni hodnoty
je tedy bodovym odhadem stredni hodnoty  v bode
v bode  chybu modelu v bode , kde je skutecna hodnota vysvetlovane promenne v bode a
chybu modelu v bode , kde je skutecna hodnota vysvetlovane promenne v bode a  je predikce v bode
je predikce v bode 
 modelu, kde v kazdem chybi
modelu, kde v kazdem chybi  priznak, znamena -krat vetsi vypocetni narocnost
priznak, znamena -krat vetsi vypocetni narocnostjako kvalitu rozdeleni (informacni zisk) typicky bereme toto:
 , kde
, kde


 se bude cilit na vektory
se bude cilit na vektory  , ktere maji co nejmensi slozky
, ktere maji co nejmensi slozky



 :
:

 , pri derivovani jsou ale
, pri derivovani jsou ale  konstanty a
konstanty a  jsou konstanty vzdy, takze
jsou konstanty vzdy, takze

Vyhody:
Nevyhody:
 funkce
funkce  promennych
promennych podle promenne
podle promenne  v bode
v bode  definujeme jako derivaci funkce
definujeme jako derivaci funkce  v bode
v bode  a znacime:
a znacime:

 v bode
v bode  konecne vsechny parcialni derivace, pak definujme gradient funkce v bode
konecne vsechny parcialni derivace, pak definujme gradient funkce v bode  jako vektor
jako vektor

v bode definujeme takto:
 ma v radku
ma v radku  hodnotu
hodnotu  funkce promennych a bod
funkce promennych a bod  takovy, ze
takovy, ze  a ma na
a ma na  spojite vsechny druhe parcialni derivace
spojite vsechny druhe parcialni derivace , tedy matice je pozitivne semi-definitni, pak nabyva funkce v bode
, tedy matice je pozitivne semi-definitni, pak nabyva funkce v bode  ostreho lokalniho minima
ostreho lokalniho minima
paru nezavislych trenovacich dat  ze stejneho rozdeleni, ktera pochazeji z naseho modelu, tedy
ze stejneho rozdeleni, ktera pochazeji z naseho modelu, tedy 
 ,
,  a body
a body  zapisme po radcich do matice
zapisme po radcich do matice  :
:


 , aby se dal delat rozumny odhad a zabranilo se sumu a preuceni muze na druhou stranu zpusobit, ze se koukame na prilis mnoho bodu v datasetu, ktere uz tim padem vlastne nejsou az tak blizko bodu, ktery predikujeme
, aby se dal delat rozumny odhad a zabranilo se sumu a preuceni muze na druhou stranu zpusobit, ze se koukame na prilis mnoho bodu v datasetu, ktere uz tim padem vlastne nejsou az tak blizko bodu, ktery predikujeme ) delka intervalu, pokud bychom udelali dokonalou krychli, aby zabirala rekneme
) delka intervalu, pokud bychom udelali dokonalou krychli, aby zabirala rekneme  celkoveho objemu:
celkoveho objemu:
 je to
je to  , pro
, pro  je to
je to ![\sqrt[2]{0.1} = 0.316](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEzLjE3N2V4IiBoZWlnaHQ9IjMuNTA5ZXgiIHN0eWxlPSJ2ZXJ0aWNhbC1hbGlnbjogLTAuODM4ZXg7IiB2aWV3Qm94PSIwIC0xMTUwLjEgNTY3My42IDE1MTAuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtU1RJWFdFQk1BSU4tMzAiIGQ9Ik00NzYgMzMwYzAgLTE3MiAtNjMgLTM0NCAtMjI2IC0zNDRjLTE3MSAwIC0yMjYgMTg2IC0yMjYgMzUwYzAgMTc3IDY5IDM0MCAyMzAgMzQwYzEzMSAwIDIyMiAtMTQxIDIyMiAtMzQ2ek0zODAgMzI1YzAgMjA4IC00NCAzMjUgLTEzMiAzMjVjLTgzIDAgLTEyOCAtMTE4IC0xMjggLTMyMXM0NCAtMzE3IDEzMCAtMzE3Yzg1IDAgMTMwIDExNSAxMzAgMzEzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1TVElYV0VCTUFJTi0yRSIgZD0iTTE4MSA0M2MwIC0yOSAtMjYgLTU0IC01NiAtNTRjLTMxIDAgLTU1IDI0IC01NSA1NXMyNSA1NiA1NiA1NmMyOSAwIDU1IC0yNyA1NSAtNTdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLVNUSVhXRUJNQUlOLTMxIiBkPSJNMzk0IDBoLTI3NnYxNWM3NCA0IDk1IDI1IDk1IDgwdjQ0OWMwIDM0IC05IDQ5IC0zMCA0OWMtMTAgMCAtMjcgLTUgLTQ1IC0xMmwtMjcgLTEwdjE0bDE3OSA5MWw5IC0zdi01OTdjMCAtNDMgMjAgLTYxIDk1IC02MXYtMTVaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLVNUSVhXRUJNQUlOLTIyMUEiIGQ9Ik05NjMgOTczbC00NzggLTEyMzJoLTMybC0yMDIgNTMwYy0xNyA0NSAtMzcgNTkgLTYyIDU5Yy0xNyAwIC00MyAtMTEgLTY1IC0zMWwtMTIgMjBsMTU2IDEyNGgxOWwyMDQgLTUzNmg0bDQxNCAxMDY2aDU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1TVElYV0VCTUFJTi0zMiIgZD0iTTQ3NCAxMzdsLTU0IC0xMzdoLTM5MXYxMmwxNzggMTg5Yzk0IDk5IDEzMCAxNzUgMTMwIDI2MGMwIDkxIC01NCAxNDEgLTEzOSAxNDFjLTcyIDAgLTEwNyAtMzIgLTE0NyAtMTMwbC0yMSA1YzIxIDExNyA4NSAxOTkgMjA4IDE5OWMxMTMgMCAxODUgLTc3IDE4NSAtMTc2YzAgLTc5IC0zOSAtMTU0IC0xMjggLTI0OGwtMTY1IC0xNzZoMjM0YzQyIDAgNjMgMTEgOTYgNjdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLVNUSVhXRUJNQUlOLTNEIiBkPSJNNjM3IDMyMGgtNTg5djY2aDU4OXYtNjZ6TTYzNyAxMjBoLTU4OXY2Nmg1ODl2LTY2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1TVElYV0VCTUFJTi0zMyIgZD0iTTYxIDUxMGwtMTYgNGMyOSA5NSA5MiAxNjIgMTk2IDE2MmM5MyAwIDE1NiAtNTUgMTU2IC0xMzdjMCAtNDggLTI2IC05OCAtOTMgLTEzOGM0NCAtMTkgNjIgLTMxIDgzIC01M2MyOCAtMzEgNDQgLTc3IDQ0IC0xMjljMCAtNTMgLTE3IC0xMDIgLTQ2IC0xNDBjLTQ4IC02NCAtMTQzIC05MyAtMjMyIC05M2MtNzMgMCAtMTEyIDIxIC0xMTIgNTdjMCAyMSAxOCAzNiA0MSAzNmMxNyAwIDMzIC02IDYxIC0yNmMzNyAtMjYgNTggLTMxIDg2IC0zMSBjNzQgMCAxMzAgNjggMTMwIDE1M2MwIDc2IC0zNSAxMjUgLTEwNCAxNDVjLTIyIDcgLTQ1IDEwIC0xMDIgMTB2MTRjMzggMTMgNjQgMjQgODQgMzZjNDkgMjggODEgNzMgODEgMTM0YzAgNjggLTQyIDEwMiAtMTA4IDEwMmMtNjIgMCAtMTA4IC0zMiAtMTQ5IC0xMDZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLVNUSVhXRUJNQUlOLTM2IiBkPSJNNDQ2IDY4NGwyIC0xNmMtMTU3IC0yNiAtMjY5IC0xMzQgLTI5NiAtMjg1YzQ5IDM4IDgzIDQ1IDEyNyA0NWMxMTcgMCAxODkgLTgwIDE4OSAtMjA5YzAgLTY0IC0xOCAtMTIwIC01MSAtMTYwYy0zNyAtNDYgLTkzIC03MyAtMTU5IC03M2MtNzkgMCAtMTQyIDM3IC0xNzcgMTAxYy0yOCA1MSAtNDcgMTIyIC00NyAxOTJjMCAxMDggMzggMjAzIDEwOSAyNzZjODYgOTAgMTY1IDExNCAzMDMgMTI5ek0zNzggMTg4IGMwIDEyOCAtNDIgMTk0IC0xMzUgMTk0Yy01NyAwIC0xMTYgLTI0IC0xMTYgLTExNmMwIC0xNTIgNDggLTI1MiAxNDIgLTI1MmM3MiAwIDEwOSA3MiAxMDkgMTc0WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtU1RJWFdFQk1BSU4tMzIiIHg9IjU3NiIgeT0iODE5Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJNQUlOLTIyMUEiIHg9IjAiIHk9Ii0yMCI+PC91c2U+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEyNTEiIGhlaWdodD0iNjAiIHg9IjkyOCIgeT0iODk0Ij48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkyOCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTUFJTi0zMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTUFJTi0yRSIgeD0iNTAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJNQUlOLTMxIiB4PSI3NTEiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTUFJTi0zRCIgeD0iMjQ1NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MjEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQk1BSU4tMzAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQk1BSU4tMkUiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTUFJTi0zMyIgeD0iNzUxIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJNQUlOLTMxIiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJNQUlOLTM2IiB4PSIxNzUyIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==) , pro
, pro  je to
je to ![\sqrt[3]{0.464}](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjcuMzg4ZXgiIGhlaWdodD0iMy41MDlleCIgc3R5bGU9InZlcnRpY2FsLWFsaWduOiAtMC44MzhleDsiIHZpZXdCb3g9IjAgLTExNTAuMSAzMTgxIDE1MTAuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtU1RJWFdFQk1BSU4tMzAiIGQ9Ik00NzYgMzMwYzAgLTE3MiAtNjMgLTM0NCAtMjI2IC0zNDRjLTE3MSAwIC0yMjYgMTg2IC0yMjYgMzUwYzAgMTc3IDY5IDM0MCAyMzAgMzQwYzEzMSAwIDIyMiAtMTQxIDIyMiAtMzQ2ek0zODAgMzI1YzAgMjA4IC00NCAzMjUgLTEzMiAzMjVjLTgzIDAgLTEyOCAtMTE4IC0xMjggLTMyMXM0NCAtMzE3IDEzMCAtMzE3Yzg1IDAgMTMwIDExNSAxMzAgMzEzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1TVElYV0VCTUFJTi0yRSIgZD0iTTE4MSA0M2MwIC0yOSAtMjYgLTU0IC01NiAtNTRjLTMxIDAgLTU1IDI0IC01NSA1NXMyNSA1NiA1NiA1NmMyOSAwIDU1IC0yNyA1NSAtNTdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLVNUSVhXRUJNQUlOLTM0IiBkPSJNNDczIDE2N2gtMTAzdi0xNjdoLTc4djE2N2gtMjgwdjY0bDMxNCA0NDVoNDR2LTQ0NWgxMDN2LTY0ek0yOTIgMjMxdjM0M2wtMjQwIC0zNDNoMjQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1TVElYV0VCTUFJTi0zNiIgZD0iTTQ0NiA2ODRsMiAtMTZjLTE1NyAtMjYgLTI2OSAtMTM0IC0yOTYgLTI4NWM0OSAzOCA4MyA0NSAxMjcgNDVjMTE3IDAgMTg5IC04MCAxODkgLTIwOWMwIC02NCAtMTggLTEyMCAtNTEgLTE2MGMtMzcgLTQ2IC05MyAtNzMgLTE1OSAtNzNjLTc5IDAgLTE0MiAzNyAtMTc3IDEwMWMtMjggNTEgLTQ3IDEyMiAtNDcgMTkyYzAgMTA4IDM4IDIwMyAxMDkgMjc2Yzg2IDkwIDE2NSAxMTQgMzAzIDEyOXpNMzc4IDE4OCBjMCAxMjggLTQyIDE5NCAtMTM1IDE5NGMtNTcgMCAtMTE2IC0yNCAtMTE2IC0xMTZjMCAtMTUyIDQ4IC0yNTIgMTQyIC0yNTJjNzIgMCAxMDkgNzIgMTA5IDE3NFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtU1RJWFdFQk1BSU4tMjIxQSIgZD0iTTk2MyA5NzNsLTQ3OCAtMTIzMmgtMzJsLTIwMiA1MzBjLTE3IDQ1IC0zNyA1OSAtNjIgNTljLTE3IDAgLTQzIC0xMSAtNjUgLTMxbC0xMiAyMGwxNTYgMTI0aDE5bDIwNCAtNTM2aDRsNDE0IDEwNjZoNTRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLVNUSVhXRUJNQUlOLTMzIiBkPSJNNjEgNTEwbC0xNiA0YzI5IDk1IDkyIDE2MiAxOTYgMTYyYzkzIDAgMTU2IC01NSAxNTYgLTEzN2MwIC00OCAtMjYgLTk4IC05MyAtMTM4YzQ0IC0xOSA2MiAtMzEgODMgLTUzYzI4IC0zMSA0NCAtNzcgNDQgLTEyOWMwIC01MyAtMTcgLTEwMiAtNDYgLTE0MGMtNDggLTY0IC0xNDMgLTkzIC0yMzIgLTkzYy03MyAwIC0xMTIgMjEgLTExMiA1N2MwIDIxIDE4IDM2IDQxIDM2YzE3IDAgMzMgLTYgNjEgLTI2YzM3IC0yNiA1OCAtMzEgODYgLTMxIGM3NCAwIDEzMCA2OCAxMzAgMTUzYzAgNzYgLTM1IDEyNSAtMTA0IDE0NWMtMjIgNyAtNDUgMTAgLTEwMiAxMHYxNGMzOCAxMyA2NCAyNCA4NCAzNmM0OSAyOCA4MSA3MyA4MSAxMzRjMCA2OCAtNDIgMTAyIC0xMDggMTAyYy02MiAwIC0xMDggLTMyIC0xNDkgLTEwNloiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNTc0KSIgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJNQUlOLTMzIiB4PSI2MTkiIHk9IjgyNiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTUFJTi0yMjFBIiB4PSIwIiB5PSItMTYiPjwvdXNlPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIyMjUyIiBoZWlnaHQ9IjYwIiB4PSI5MjgiIHk9Ijg5OCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5MjgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQk1BSU4tMzAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQk1BSU4tMkUiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTUFJTi0zNCIgeD0iNzUxIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJNQUlOLTM2IiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJNQUlOLTM0IiB4PSIxNzUyIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==) , pro
, pro  je to
je to ![\sqrt[50]{0.1} = 0.955](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEzLjE3N2V4IiBoZWlnaHQ9IjMuNTA5ZXgiIHN0eWxlPSJ2ZXJ0aWNhbC1hbGlnbjogLTAuODM4ZXg7IiB2aWV3Qm94PSIwIC0xMTUwLjEgNTY3My42IDE1MTAuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtU1RJWFdFQk1BSU4tMzAiIGQ9Ik00NzYgMzMwYzAgLTE3MiAtNjMgLTM0NCAtMjI2IC0zNDRjLTE3MSAwIC0yMjYgMTg2IC0yMjYgMzUwYzAgMTc3IDY5IDM0MCAyMzAgMzQwYzEzMSAwIDIyMiAtMTQxIDIyMiAtMzQ2ek0zODAgMzI1YzAgMjA4IC00NCAzMjUgLTEzMiAzMjVjLTgzIDAgLTEyOCAtMTE4IC0xMjggLTMyMXM0NCAtMzE3IDEzMCAtMzE3Yzg1IDAgMTMwIDExNSAxMzAgMzEzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1TVElYV0VCTUFJTi0yRSIgZD0iTTE4MSA0M2MwIC0yOSAtMjYgLTU0IC01NiAtNTRjLTMxIDAgLTU1IDI0IC01NSA1NXMyNSA1NiA1NiA1NmMyOSAwIDU1IC0yNyA1NSAtNTdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLVNUSVhXRUJNQUlOLTMxIiBkPSJNMzk0IDBoLTI3NnYxNWM3NCA0IDk1IDI1IDk1IDgwdjQ0OWMwIDM0IC05IDQ5IC0zMCA0OWMtMTAgMCAtMjcgLTUgLTQ1IC0xMmwtMjcgLTEwdjE0bDE3OSA5MWw5IC0zdi01OTdjMCAtNDMgMjAgLTYxIDk1IC02MXYtMTVaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLVNUSVhXRUJNQUlOLTIyMUEiIGQ9Ik05NjMgOTczbC00NzggLTEyMzJoLTMybC0yMDIgNTMwYy0xNyA0NSAtMzcgNTkgLTYyIDU5Yy0xNyAwIC00MyAtMTEgLTY1IC0zMWwtMTIgMjBsMTU2IDEyNGgxOWwyMDQgLTUzNmg0bDQxNCAxMDY2aDU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1TVElYV0VCTUFJTi0zNSIgZD0iTTQzOCA2ODFsLTM2IC04NWMtMyAtNyAtMTEgLTEzIC0yNyAtMTNoLTE5NGwtNDAgLTg1YzE0MyAtMjcgMTkzIC00OSAyNTAgLTEyOGMyNiAtMzYgMzUgLTc0IDM1IC0xMjdjMCAtOTYgLTMwIC0xNTggLTk4IC0yMDhjLTQ3IC0zNCAtMTAyIC00OSAtMTcwIC00OWMtNzUgMCAtMTI3IDI0IC0xMjcgNjJjMCAyNSAxNyAzOCA0NSAzOGMyMyAwIDQyIC01IDc0IC0zMWMyOCAtMjMgNTEgLTMyIDcxIC0zMmM3MCAwIDEzNSA4MyAxMzUgMTY5IGMwIDY0IC0yMiAxMTQgLTY3IDE1MGMtNDcgMzggLTExNyA3MCAtMjEzIDcwYy05IDAgLTEyIDIgLTEyIDhjMCAyIDEgNSAxIDVsMTA5IDIzN2gyMDdjMjMgMCAzMiA1IDQ4IDI2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1TVElYV0VCTUFJTi0zRCIgZD0iTTYzNyAzMjBoLTU4OXY2Nmg1ODl2LTY2ek02MzcgMTIwaC01ODl2NjZoNTg5di02NloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtU1RJWFdFQk1BSU4tMzkiIGQ9Ik01OSAtMjJsLTMgMjBjMTUyIDI3IDI2NCAxMzIgMzA0IDI5NmMtNDMgLTQyIC05MSAtNTcgLTE1MCAtNTdjLTEwOCAwIC0xODAgODEgLTE4MCAyMDNjMCAxMzUgODkgMjM2IDIwOCAyMzZjNjQgMCAxMTggLTI4IDE1NyAtNzZjNDAgLTUwIDY0IC0xMjIgNjQgLTIwNmMwIC0xMTUgLTQwIC0yMjQgLTEyMCAtMjk3Yy04NSAtNzcgLTE1MCAtMTAxIC0yODAgLTExOXpNMzYyIDM1NXYzOWMwIDE2OCAtNDUgMjU0IC0xMzIgMjU0IGMtMzAgMCAtNTYgLTEyIC03MyAtMzRjLTIwIC0yNyAtMzUgLTg2IC0zNSAtMTQwYzAgLTExOSA0OCAtMTk0IDEyMyAtMTk0YzQ0IDAgMTE3IDIyIDExNyA3NVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0Miw0NzApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjU3NCkiIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTUFJTi0zNSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtU1RJWFdFQk1BSU4tMzAiIHg9IjUwMCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJNQUlOLTIyMUEiIHg9IjAiIHk9Ii0yMCI+PC91c2U+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEyNTEiIGhlaWdodD0iNjAiIHg9IjkyOCIgeT0iODk0Ij48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkyOCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTUFJTi0zMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTUFJTi0yRSIgeD0iNTAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJNQUlOLTMxIiB4PSI3NTEiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTUFJTi0zRCIgeD0iMjQ1NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MjEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQk1BSU4tMzAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtU1RJWFdFQk1BSU4tMkUiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1TVElYV0VCTUFJTi0zOSIgeD0iNzUxIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJNQUlOLTM1IiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLVNUSVhXRUJNQUlOLTM1IiB4PSIxNzUyIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==) atd.
atd.Forward selection:
 , vezmeme po jednom z priznaku
, vezmeme po jednom z priznaku  , natrenujeme pro ruzne mnoziny priznaku
, natrenujeme pro ruzne mnoziny priznaku  a vratime
a vratime  , jehoz pridani zpusobilo nejlepsi validacni presnost
, jehoz pridani zpusobilo nejlepsi validacni presnost a opakujeme predchozi bod s mnozinou jeste nevybranych priznaku
a opakujeme predchozi bod s mnozinou jeste nevybranych priznaku krat rychlost natrenovani jednoho modelu
krat rychlost natrenovani jednoho modeluBackward selection:
Tvrzeni:
 plati
plati 
 je geometricky stred (centroid) mnoziny
je geometricky stred (centroid) mnoziny  - tedy ze
- tedy ze  je optimalni
je optimalni Dukaz:
Pro kazde  , protoze
, protoze  , plati:
, plati:

 a
a  z toho plyne
z toho plyne


 a
a  , dostaneme prvni clen a po vyscitani pres dostaneme:
, dostaneme prvni clen a po vyscitani pres dostaneme:

, znacime  , je zobrazeni
, je zobrazeni  (vsimneme si znaceni
(vsimneme si znaceni  - zobrazeni do nezapornych realnych cisel), ktere pro kazde
- zobrazeni do nezapornych realnych cisel), ktere pro kazde  a kazde
a kazde  splnuje nasledujici axiomy:
splnuje nasledujici axiomy:





 pro kazde
pro kazde 


- pocet sousedu, metrika  nejblizsich sousedu podle metriky a predikuje se v pripade binarni klasifikace majoritou, v pripade regrese prumerem
nejblizsich sousedu podle metriky a predikuje se v pripade binarni klasifikace majoritou, v pripade regrese prumerem
 , ktere berou aktualni priznaky a vytvorit z nich nove priznaky:
, ktere berou aktualni priznaky a vytvorit z nich nove priznaky:

 , hledame bod
, hledame bod  v podprostoru sloupcu matice
v podprostoru sloupcu matice  , ktery je k
, ktery je k  nejblize je k nejblize, jestlize je vektor
nejblize je k nejblize, jestlize je vektor  na ten podprostor kolmy (ortogonalni projekce)
na ten podprostor kolmy (ortogonalni projekce)



 , ziskame tzv. normalni rovnici:
, ziskame tzv. normalni rovnici: 
 -
-  je konstanta apod.:
je konstanta apod.:


 plati:
plati:  priznaku a oznacme
priznaku a oznacme  prostor, ve kterem se nachazeji mozne vysledky
prostor, ve kterem se nachazeji mozne vysledky
 spojitych priznaku typicky volime
spojitych priznaku typicky volime 
 0 chceme ziskat odhad pravdepodobnosti
0 chceme ziskat odhad pravdepodobnosti  pro kazdou (rozumnou) podmnozinu
pro kazdou (rozumnou) podmnozinu 
1. bokem si oddelime testovaci data
2. zbytek trenovacich dat
3. pro kazdou kombinaci hyperparametru:
4. for J in 1..k:
5. natrenuj model na datechs hyperparametry
6. na mnozineodhadni chybu jako
7. spocitej cross-validacni chybu pro
8. vrat kombinaci hyperparametru
 hledame rozklad
hledame rozklad  na prostoru vybavenem eukleidovskou vzdalenosti, ktery minimalizuje ucelovou funkci
na prostoru vybavenem eukleidovskou vzdalenosti, ktery minimalizuje ucelovou funkci  :
:

s metrikou 
rozklad mnoziny dat na jednotlive shluky:  , ktere tvori disjunktni sjednoceni
, ktere tvori disjunktni sjednoceni
Tvrzeni:
Dukaz:

 . Vytvorme nove shluky
. Vytvorme nove shluky  tak, ze bod presunume do takoveho shluku
tak, ze bod presunume do takoveho shluku  , ve kterem je vzdalenost
, ve kterem je vzdalenost  nejmensi
nejmensi

 pro nejake
pro nejake 
Co s tim?
 muzeme menit, coz zpusobi, ze bude potreba vic/min nez
muzeme menit, coz zpusobi, ze bude potreba vic/min nez  jednicek pro predikci 1
jednicek pro predikci 1 predikujeme same 1,tedy
predikujeme same 1,tedy  ,
, 
 zmensovalo
zmensovalo  na ukor
na ukor  , tedy aby se spravne napravovaly predikce a az pak se spatne predikovalo
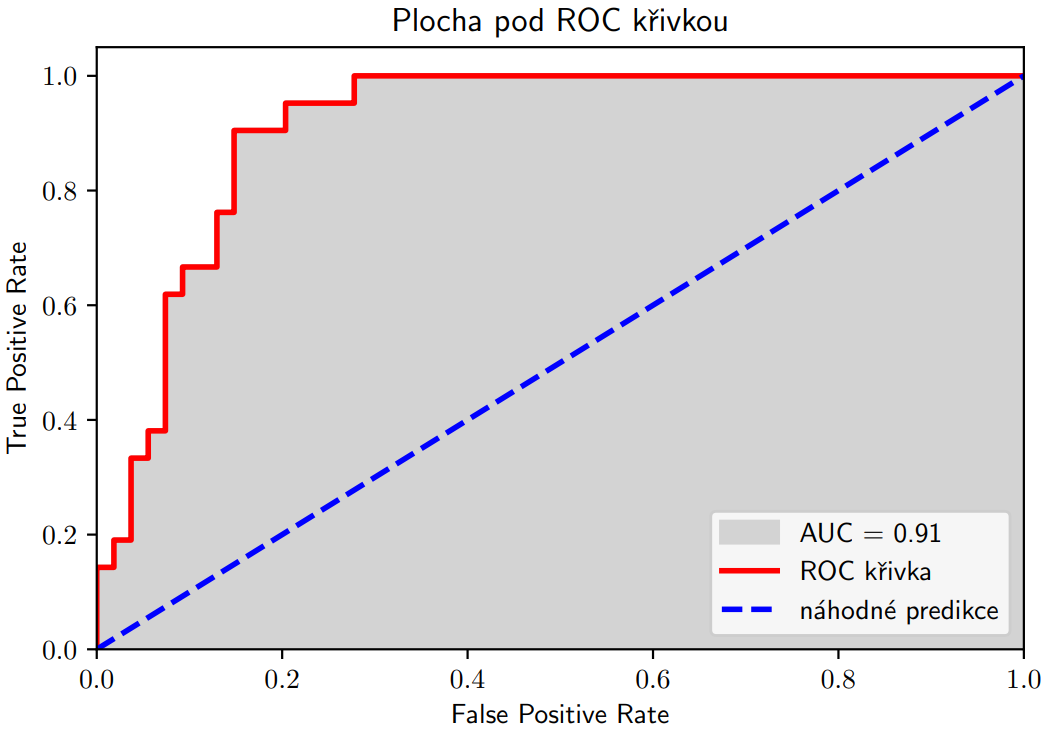
, tedy aby se spravne napravovaly predikce a az pak se spatne predikovalo  se nazyva receiver operating characteristic (ROC krivka):, ktery resi normalni rovnici a zaroven ma co nejmensi normu. Proc to je dobre?
se nazyva receiver operating characteristic (ROC krivka):, ktery resi normalni rovnici a zaroven ma co nejmensi normu. Proc to je dobre? , tedy rovnice je ve tvaru
, tedy rovnice je ve tvaru  , oznacme
, oznacme  , zaroven tedy
, zaroven tedy 
 (napr.
(napr.  a ma velkou normu (treba
a ma velkou normu (treba  -krat), predikce by se zvetsila o dost vic, nez jak by se zmenila pro mensi
-krat), predikce by se zvetsila o dost vic, nez jak by se zmenila pro mensi 
 je regularni, pak reseni existuje prave 1 (jinak jich existuje nekonecne mnoho) a normalni rovnice
je regularni, pak reseni existuje prave 1 (jinak jich existuje nekonecne mnoho) a normalni rovnice


 nikdy nemuze
nikdy nemuze  vyjit nulove, Hessova matice je tedy pozitivne definitni a je tedy jedinym globalnim minimem
vyjit nulove, Hessova matice je tedy pozitivne definitni a je tedy jedinym globalnim minimemAlgoritmus:
stredovych bodu  prirad do shluku se stredovym bodem
prirad do shluku se stredovym bodem  takovym, ze
takovym, ze  je minimalni
je minimalni : prepocitej stredovy bod
: prepocitej stredovy bod  jako geometricky stred prislusneho shluku
jako geometricky stred prislusneho shlukuJak vybrat pocatecni stredove body?
Jak zvolit ?
iterovat, dokud tento graf od bude rozumne klesat
 jako relativni pocet reprezentantu tridy z trenovaci mnoziny v listu (jak moc si je jisty)
jako relativni pocet reprezentantu tridy z trenovaci mnoziny v listu (jak moc si je jisty)


dvojic  :
:

Evaluacni miry:
 - neni vhodna pro nevybalancovane datasety (jinak staci udelat model, ktery predikuje castejsi variantou nezavisle na dalsich vstupnich parametrech a byl by podle tohoto kriteria "dobry", coz je nesmysl)
- neni vhodna pro nevybalancovane datasety (jinak staci udelat model, ktery predikuje castejsi variantou nezavisle na dalsich vstupnich parametrech a byl by podle tohoto kriteria "dobry", coz je nesmysl) a recall:
a recall:  , vhodne predevsim pro nevybalancovane datasety, v tomto pripade, kde
, vhodne predevsim pro nevybalancovane datasety, v tomto pripade, kde  je mensi nez
je mensi nez  :
:

Poznamky:
s vynechanim interceptu:

 mame linearni regresi cilime na nizsi normu vektoru
mame linearni regresi cilime na nizsi normu vektoruZavedme matici





 :
:

 mame
mame 
 je pozitivne definitni a
je pozitivne definitni a  je regularni tedy vzdy existuje jednoznacne reseni normalni rovnice
je regularni tedy vzdy existuje jednoznacne reseni normalni rovnice  a odpovida globalnimu minimu
a odpovida globalnimu minimu  je potom
je potom 
 na metrickem prostoru s metrikou
na metrickem prostoru s metrikou  a pro libovolny bod
a pro libovolny bod  oznacme
oznacme  index shluku, do ktereho
index shluku, do ktereho  patri, tj.
patri, tj.  ted muzeme:
ted muzeme:
 jako prumernou vzdalenost bodu od vsech ostatnich bodu ve shluku (krome
jako prumernou vzdalenost bodu od vsech ostatnich bodu ve shluku (krome  , "vnitrni rozdilnost")
, "vnitrni rozdilnost") spocitat prumernou vzdalenost bodu od vsech bodu v
spocitat prumernou vzdalenost bodu od vsech bodu v  , znacime
, znacime 
 jako minimum z techto prumernych vzdalenosti od ostatnich shluku:
jako minimum z techto prumernych vzdalenosti od ostatnich shluku:

ziskame vztahem

 pro kazde
pro kazde  mnozinu vsech shluku v (vzhledem k )
mnozinu vsech shluku v (vzhledem k ) bodu z (
bodu z ( ), ktere nejsou v zadnem ze shluku, nazyvame sumem:
), ktere nejsou v zadnem ze shluku, nazyvame sumem:

s hodnotami 0 a 1 a priznaku  s konstantnim
s konstantnim 
 a pro koeficienty
a pro koeficienty  ma tvar
ma tvar

 , jinak 0 sloupcu pro
, jinak 0 sloupcu pro  datovych bodu znamena, ze sloupcu v podprostoru o dimenzi
datovych bodu znamena, ze sloupcu v podprostoru o dimenzi  proste LZ budou - intercept), je LZ na sloupcich one-hot encodingu
proste LZ budou - intercept), je LZ na sloupcich one-hot encodingu a plati
a plati 


s metrikou , ze ktereho pochazi dataset a parametry  a
a  -okoli bodu v jako mnozinu
-okoli bodu v jako mnozinu

je klicovy bod, jestlize v jeho -okoli v je alespon  bodu, tzn.
bodu, tzn.

 je primo dosazitelny z bodu , jestlize je klicovy bod a
je primo dosazitelny z bodu , jestlize je klicovy bod a  , tj. ma alespon bodu v okoli a
, tj. ma alespon bodu v okoli a  je jeden z nich je dosazitelny z bodu , pokud v grafu relace prime dosazitelnosti existuje orientovana --cesta je spojeny s bodem , jestlize existuje klicovy bod
je jeden z nich je dosazitelny z bodu , pokud v grafu relace prime dosazitelnosti existuje orientovana --cesta je spojeny s bodem , jestlize existuje klicovy bod  takovy, ze i jsou dosazitelne z bodu (tzn. existuje orientovana --cesta a orientovana --cesta a orientovana --cesta), jde o symetrickou relaci a pro klicove body i tranzitivni
takovy, ze i jsou dosazitelne z bodu (tzn. existuje orientovana --cesta a orientovana --cesta a orientovana --cesta), jde o symetrickou relaci a pro klicove body i tranzitivni takove, ze
takove, ze  jsou spojene a je klicovy, pak je dosazitelny z
jsou spojene a je klicovy, pak je dosazitelny z  je neprazdna podmnozina takova, ze
plati, ze pokud
je neprazdna podmnozina takova, ze
plati, ze pokud  a je dosazitelny z , pak
a je dosazitelny z , pak 
 je spojeny s (souvislost)
je spojeny s (souvislost)
v zavislosti na hodnotach priznaku datoveho bodu vyjadrime jako

 takovy, aby byl tento odhad pravdepodobnosti pomoci pro vstupni datovy bod co nejblize skutecne pravdepodobnosti
takovy, aby byl tento odhad pravdepodobnosti pomoci pro vstupni datovy bod co nejblize skutecne pravdepodobnostiVazene trenovani:
se napr. pro vypocet entropie  pouzije odhad pravdepodobnosti tridy 1 urceny souctem vah bodu ve tride 1, ktere spadaji do
pouzije odhad pravdepodobnosti tridy 1 urceny souctem vah bodu ve tride 1, ktere spadaji do  , podeleny souctem vah vsech bodu v , lze delat podobne i pro regresni ulohu
, podeleny souctem vah vsech bodu v , lze delat podobne i pro regresni ulohu  , pak soucet vah pro je
, pak soucet vah pro je  , soucet vsech vah je
, soucet vsech vah je  , tedy pravdepodobnost tridy je v tomto pripade
, tedy pravdepodobnost tridy je v tomto pripade 
 (
( obdobne) spocita jako
obdobne) spocita jako

Vazena predikce:
, pokud soucet vah pro nadpolovicni, nez soucet vsech vahPoznamka:

 (viz nize) jako pravdepodobnost, ze datovy bod nabyval hodnoty :
(viz nize) jako pravdepodobnost, ze datovy bod nabyval hodnoty :

 jako pravdepodobnost, ze datovy bod nabyval hodnoty
jako pravdepodobnost, ze datovy bod nabyval hodnoty  :
:

 -ty datovy bod tedy skutecne nabyval hodnoty (skutecne hodnoty, ktera nastala), se tedy da vypocitat jako
-ty datovy bod tedy skutecne nabyval hodnoty (skutecne hodnoty, ktera nastala), se tedy da vypocitat jako

a muzeme tedy v zavislosti na parametrech tuto pravdepodobnost odhadnout jako

, pro ktery je nejvetsi sance, ze trenovaci data nabyvala takovych hodnot, nez pro kterekoliv jine  .
.
 - stejne jako u linearni regrese nejaky intercept + koeficienty priznaku (tedy vektor
- stejne jako u linearni regrese nejaky intercept + koeficienty priznaku (tedy vektor  ) a naopak cim dal jsme od hranice na druhou stranu, tim mensi hodnota chceme nejak rozumne vmestnat do moznych hodnot , coz je interval
) a naopak cim dal jsme od hranice na druhou stranu, tim mensi hodnota chceme nejak rozumne vmestnat do moznych hodnot , coz je interval  , a to tak, aby nepresnost u hodne kladne nebo hodne zaporna hodnota nezmenila fakt, ze ta si je model hodne jisty
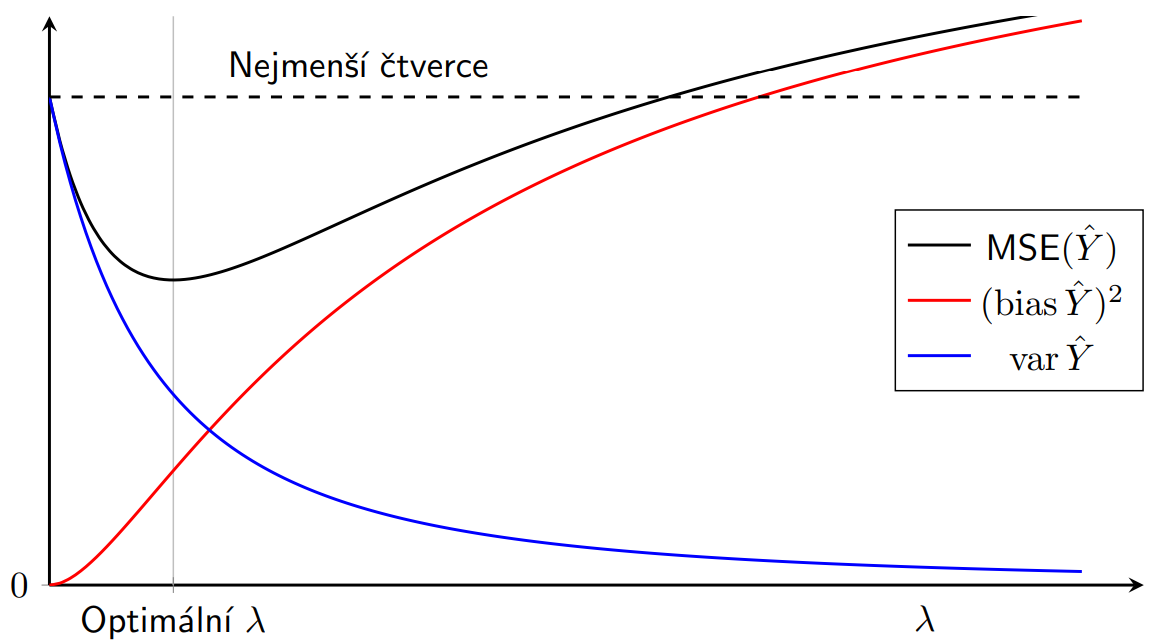
, a to tak, aby nepresnost u hodne kladne nebo hodne zaporna hodnota nezmenila fakt, ze ta si je model hodne jisty vychyleni roste a rozptyl klesa:
mame beznou linearni regresi: nejvetsi rozptyl, zadny bias nas logicky zajima norma tech koeficientu, tzn. data nas zajimaji min a min → rozptyl klesa, ale mame vetsi systematickou chybu (budeme systematicky predikovat o neco jinak)
vychyleni roste a rozptyl klesa:
mame beznou linearni regresi: nejvetsi rozptyl, zadny bias nas logicky zajima norma tech koeficientu, tzn. data nas zajimaji min a min → rozptyl klesa, ale mame vetsi systematickou chybu (budeme systematicky predikovat o neco jinak) se snizuje taky rozptyl a zvetsuje bias shluku, pak dendrogram usekneme pod
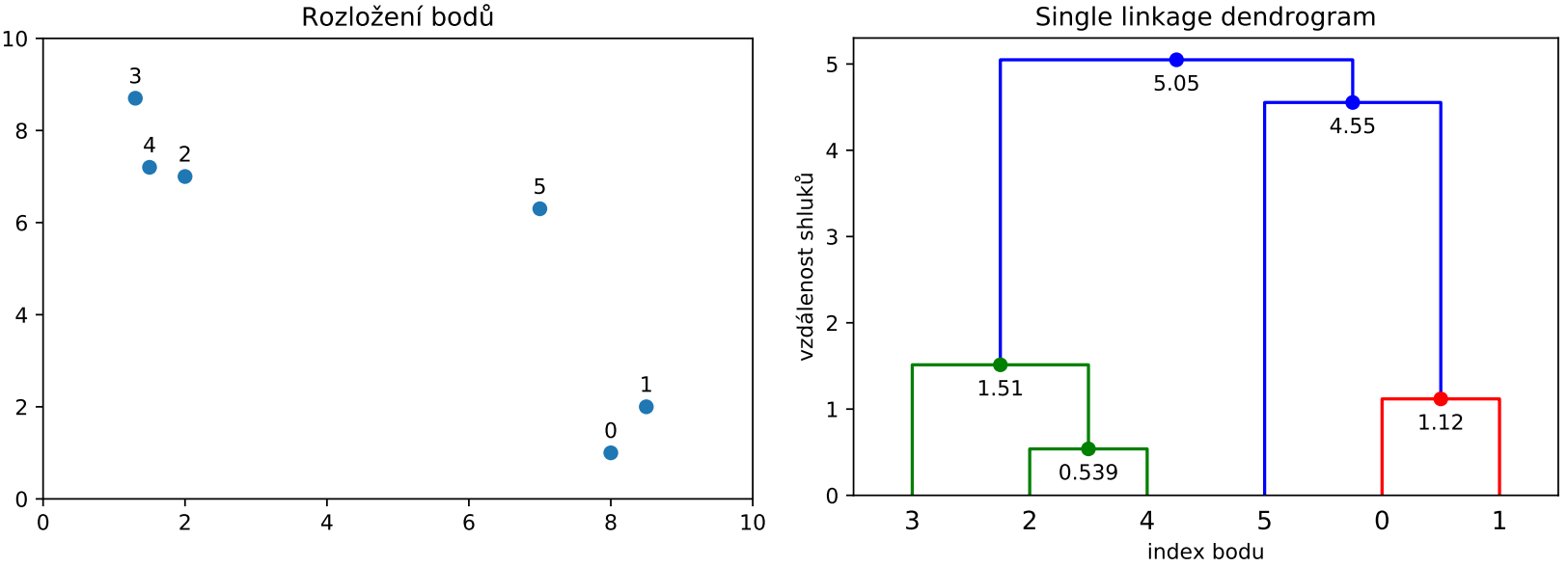
se snizuje taky rozptyl a zvetsuje bias shluku, pak dendrogram usekneme pod  -tym nejvyssim vrcholem (pro 1 shluk nic nesekame, pro 2 shluky pod 1., pro 3 shluky pod 2., …) a hrany, ktere toto "useknuti" protne, vedou smerem dolu do prave tech shluku-souradnice, na niz se seka, coz znaci, o kolik by se musel zvetsit threshold pro spojeni, aby se spojil ten vyssi z tech vrcholu vytvorime
-tym nejvyssim vrcholem (pro 1 shluk nic nesekame, pro 2 shluky pod 1., pro 3 shluky pod 2., …) a hrany, ktere toto "useknuti" protne, vedou smerem dolu do prave tech shluku-souradnice, na niz se seka, coz znaci, o kolik by se musel zvetsit threshold pro spojeni, aby se spojil ten vyssi z tech vrcholu vytvorime  datasetu
datasetu  (obvykle stejne velkych jako ) pomoci metody bootstrap - vyberu s opakovanim
(obvykle stejne velkych jako ) pomoci metody bootstrap - vyberu s opakovanim naucime rozhodovaci strom, typicky vybereme jen nejaky zlomek priznaku:
naucime rozhodovaci strom, typicky vybereme jen nejaky zlomek priznaku: 
 , parametry pro stromy, pomer/pocet (predem nahodne vybranych) featur, kde je nahodny vektor je nahodny vektor
, parametry pro stromy, pomer/pocet (predem nahodne vybranych) featur, kde je nahodny vektor je nahodny vektor a zkoumejme ocekavanou chybu merenou pomoci kvadraticke ztratove funkce pri predikci
a zkoumejme ocekavanou chybu merenou pomoci kvadraticke ztratove funkce pri predikci  pomoci a jsou taky nezavisle
pomoci a jsou taky nezavisle
a nezavisle a tedy i nekorelovane, a tedy kovariance je nulova
 - bayes error,
- bayes error,  - mean squared error
- mean squared error
 :
:

 vetsi nez ve jmenovateli
vetsi nez ve jmenovateli : prumerna vzdalenost k jinemu nejblizsimu clusteru je vetsi nez k aktualnimu → GOOD
: prumerna vzdalenost k jinemu nejblizsimu clusteru je vetsi nez k aktualnimu → GOOD
 v abs. hodnote vetsi nez
v abs. hodnote vetsi nez  : prumerna vzdalenost k jinemu nejblizsimu clusteru je mensi nez k aktualnimu (existuje blizsi cluster) → BAD
: prumerna vzdalenost k jinemu nejblizsimu clusteru je mensi nez k aktualnimu (existuje blizsi cluster) → BAD :
spocitej - okoli kazdeho bodu a identifikuj klicove body
:
spocitej - okoli kazdeho bodu a identifikuj klicove bodyPoznamky:
-okoli vice ruznych zarodku shluku, spadne do prvniho shluku, ke kteremu se algoritmus dostane , v mnoha realnych situacich se ale realne dostane na
, v mnoha realnych situacich se ale realne dostane na 
 , kde je typicky dulezitejsi je dobre volit 4-6, nekdy
, kde je typicky dulezitejsi je dobre volit 4-6, nekdy  , kde je pocet priznaku je dobre volit male, lze napr. volit prumernou vzdalenost bodu k jejich
, kde je pocet priznaku je dobre volit male, lze napr. volit prumernou vzdalenost bodu k jejich  -temu sousedovi lze ted napriklad zpocitat prumerne silhouette skore pro shluk , znacime
-temu sousedovi lze ted napriklad zpocitat prumerne silhouette skore pro shluk , znacime 
 pro ruzne pocty shluku muzeme pouzit k nalezeni vhodneho poctu shluku jako hodnoty, pri ktere je minimalni
pro ruzne pocty shluku muzeme pouzit k nalezeni vhodneho poctu shluku jako hodnoty, pri ktere je minimalni - nalezeni oblasti prostoru, kde se data vyskytuji s velkou pravdepodobnost
- nalezeni oblasti prostoru, kde se data vyskytuji s velkou pravdepodobnost relativne velka, tj. casto zkoumame kartezsky soucin spojitych podintervalu rozsahu jednotlivych priznaku (napr.
relativne velka, tj. casto zkoumame kartezsky soucin spojitych podintervalu rozsahu jednotlivych priznaku (napr.  pro priznak a zaroven
pro priznak a zaroven  pro priznak
pro priznak  )
) se nazyva konjunktivni pravidlo
se nazyva konjunktivni pravidlo1. Nastavme vahy rovnomerne, tedya polozme
2. Pokud:
Nauc stromna datech
3. Do promenneulozme soucet vah tech bodu z
ktere jsou spatne klasifikovane stromem
4. Pokud:
Algoritmus skonci (vsechna data jsou natrenovana spravne)
a vrati rozhodovaci stromy
5. Polozme
kdeje hyperparametr modelu zabranujici preuceni
(pokud je mensi nez 1)
pokud je malo chyb (), pak
pokud je hodne chyb (), pak
6. Pro stromem:
7. znormalizujeme vahy, aby jejich soucet byl 1
8. zvetsimeo jedna, vratime se do bodu 2
se spatne derivuje (je to polynom velkeho stupne)
 nebo
nebo  zde bude prave jeden clen a ten druhy zmizi, coz nam umoznuje kompaktnejsi zapis
zde bude prave jeden clen a ten druhy zmizi, coz nam umoznuje kompaktnejsi zapis - "analyza nakupniho kosiku" (ANK)
- "analyza nakupniho kosiku" (ANK) je bud jednoprvkova mnozina
je bud jednoprvkova mnozina  , nebo vsechny moznosti daneho priznaku
, nebo vsechny moznosti daneho priznaku  (priznak vypadne) - vybirame pouze priznaky s hodnotou 1, nikoli s hodnotou 0
(priznak vypadne) - vybirame pouze priznaky s hodnotou 1, nikoli s hodnotou 0 tak, ze tato pravdedobnost je relativne velka:
tak, ze tato pravdedobnost je relativne velka: 
 se pak nazyva mnozina polozek
se pak nazyva mnozina polozek a nazyva podpora mnoziny polozek a odpovida odhadu vyse uvedene pravdepodobnosti:
a nazyva podpora mnoziny polozek a odpovida odhadu vyse uvedene pravdepodobnosti: 
 :
:  , kterou nam algoritmus vrati, hledame vhodne rozlozeni na dve disjunktni podmnoziny
, kterou nam algoritmus vrati, hledame vhodne rozlozeni na dve disjunktni podmnoziny  , ktere budeme nazyvat asociacni pravidlo (AP) a budeme je znacit
, ktere budeme nazyvat asociacni pravidlo (AP) a budeme je znacit  , kde nazveme predpoklad a
, kde nazveme predpoklad a  nazveme zaver
nazveme zaver (rel. velikost v datasetu)
(rel. velikost v datasetu)
za podminky 

 , protoze se jedna o rozdil, muzeme oba cleny te vnejsi zavorky derivovat zvlast a odecist je od sebe
, protoze se jedna o rozdil, muzeme oba cleny te vnejsi zavorky derivovat zvlast a odecist je od sebe :
:
 je skalarni soucin:
je skalarni soucin:

 -teho clenu je konstanta (nezavisle na
-teho clenu je konstanta (nezavisle na  ) a zderivuje se na nulu, -ty clen
) a zderivuje se na nulu, -ty clen  se podle zderivuje na
se podle zderivuje na 
 , protoze je konstanta (nezavisle na ), je
, protoze je konstanta (nezavisle na ), je 
 :
:


 (bod v
(bod v  , primka pro
, primka pro  , rovina pro
, rovina pro  )
) napr. s hodnotou v prvnim a tretim kvadrantu, s hodnotou ve druhem a ctvrtem kvadrantu, nelze je nijak oddelit primkou!!!
napr. s hodnotou v prvnim a tretim kvadrantu, s hodnotou ve druhem a ctvrtem kvadrantu, nelze je nijak oddelit primkou!!! (kolikrat se zvedne pst. , pokud vime, ze nastalo :
(kolikrat se zvedne pst. , pokud vime, ze nastalo :

 - tedy jaka je pst., ze bylo zpusobene :
- tedy jaka je pst., ze bylo zpusobene :

Parametry modelu:
n: pocet lesu
k: pocet vybranych prvku
q: pocet nahodne vybranych priznaku
H: hyperparametry stromu
Trenovani(D: dataset) -> void:
1. for i = 1..n:
2. Di = []
3. Qi = vyber nahodnych q priznaku z priznaku D
4. repeat k times:
5. x = vyber nahodny prvek z D
6. Di.append(x.vyber_priznaky(Qi))
7. Ti = natrenuj strom s daty Di a hyperparametry H
Predikce(x: datovy bod) -> float
1. pro i = 1..n:
2. Yi = Ti.predict(x.vyber_priznaky(Qi))
3. return mean(Yi)
1. Kazdemu stromuz kroku 5 trenovaciho algoritmu
2. Secti vahy
a to same udelej pro stromy predikujici(vazena predikce)
3. Rozhodni se pro tu z moznosti, pro kterou je soucet vah vyssi

 znamena, ze v celem datasetu si koupilo
znamena, ze v celem datasetu si koupilo  kombinaci vsech tri produktu
kombinaci vsech tri produktu pripadu, pak spolehlivost se vypocita jako
pripadu, pak spolehlivost se vypocita jako

 pripadu si koupi i horcici a chleb
pripadu si koupi i horcici a chleb pripadu, zdvih bude
pripadu, zdvih bude 
 vetsi sance, ze si koupi horcici a chleb, nez kdyby si parky nekoupil
vetsi sance, ze si koupi horcici a chleb, nez kdyby si parky nekoupil , tedy ze
, tedy ze  lze horcici a chleb brat jako dusledek koupe parku
lze horcici a chleb brat jako dusledek koupe parku


 misto
misto  - oboji to jsou ale hodnoty predikci
- oboji to jsou ale hodnoty predikci se neda pocitat analyticky, takze se musi pouzit gradientni sestup, vicerozmerna Newtonova metoda apod.
se neda pocitat analyticky, takze se musi pouzit gradientni sestup, vicerozmerna Newtonova metoda apod.