Pruthviraj Gawande
Created by Pruthviraj Gawande
Rag chain and how chatbot works
#introduction, #newcomers, #onboarding
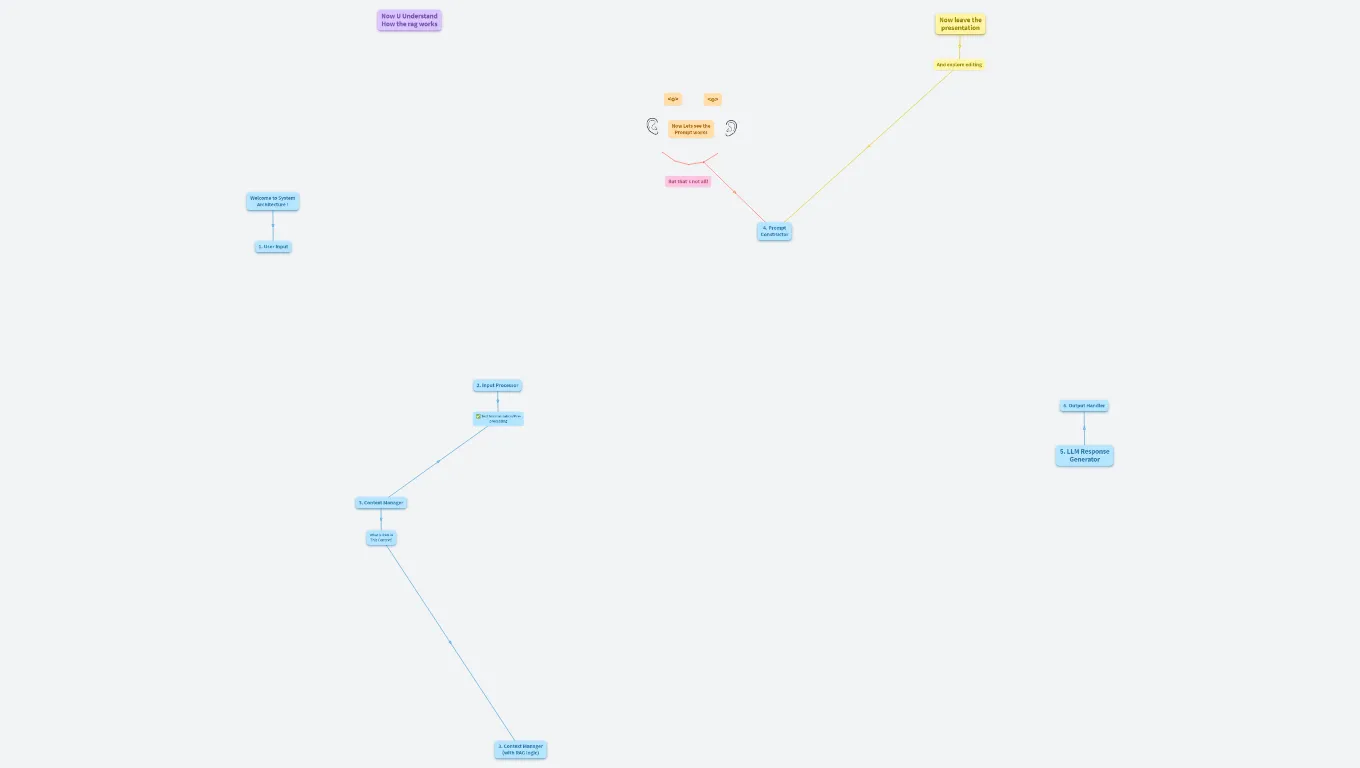
Welcome to System Architecture !
This is a System Architecture Flow for Voice-AI Telegram Assistan
1. User Input
- 🎤 Voice Input
- 💬 Text Input (Chat Box)
2. Input Processor
🧠 Speech-to-Text Module
- Library:
speech_recognition - API: Google Speech API
3. Context Manager
- 📁 Chat History Loader
- 🧠 Recent Context Extractor
get_recent_context() (RAG-like, retrieves past relevant chats)
- 🧠 Name Memory Logic
- Check and remember user's name
✅ Text Normalization/Pre-processing
What is RAG in This Context?
RAG (Retrieval-Augmented Generation) is an approach where the system retrieves relevant past information before generating a new response. In your case:
- You're retrieving relevant past conversations (from
chat_history.json) - You use them as context for the LLM
- This helps the model generate more coherent, personalized responses
3. Context Manager (with RAG logic)
- ✅ Step 1: Load History
- Uses
load_history() to access stored conversations
- 🔍 Step 2: Retrieve Relevant Context (RAG)
- Uses
get_recent_context() to extract recent/important chat snippets - E.g., "Your name is Alex" → used again when user asks “Do you remember my name?”
- 🧩 Step 3: Context + Current Input → Prompt
- Final constructed prompt:
"Role Prompt + Retrieved Context + User Input"
Now U Understand How the rag works

<o>
<o>

Now Lets see the Prompt works


But that's not all!
4. Prompt Constructor
- 🧾 Prompt from Sidebar
- 🧠 Merged Context + User Query
- Combines: prompt + context + latest user input
5. LLM Response Generator
🤖 Groq LLM API
- Models: Llama3-8b / 70b, Mixtral
- Endpoint:
client.chat.completions.create(...)
Now leave the presentation
Desktop: press Escape or hit the Exit button in the presentation menu (bottom center)
Mobile: Hit the cross icon
And explore editing
6. Output Handler
- 💬 Display in Chat UI
- 🔊 Text-to-Speech Response